
Last Updated: 11/13/2021 Saturday
How To Install Elixir
If you'd like to read this in Kindle format, check it out over here at Amazon.

The Power of Proper Tooling
As I began to acquire more expertise and experience in programming, I realized that in some ways, 50% of the battle in getting started with learning a new technology stack is getting setup with the right tooling.
I still remember the first time I setup a shortcut for setting up git status. I added a shortcut with git st. One of my coworkers showed me a shortcut gs - even shorter! Holy cow, what a difference having not to type those last few characters makes!
And that's the power of proper tooling
Proper tooling makes you more productive and makes programming more fun. I find having a proper environment manager to help you manage different releases of a language, makes it easy to test out different versions of the language. This especially holds true for an up and coming language like Elixir. So let's dive into the tools!
Overview of The Tools
Let's go over some tools you can use to manage your Elixir (and Erlang) installation. Since Elixir runs on top of Erlang, you'll want a way to easily manage both Elixir and Erlang installations. Hopefully by the end of this, you'll have everything setup and be ready to dive into the wonderful world of Elixir.
Kiex
If you've used a Ruby version manager like RVM or chruby, then you can think of kiex as being equivalent to that. Kiex is a handy little tool to let you easily install and/or switch between Elixir versions. And as Elixir is a fairly new language, it's constantly being updated.
Kerl
Kerl is the tool that lets you easily switch out and build different Erlang versions. It's a pretty handy tool to have since newer versions of Elixir keep using newer versions of Erlang. For example, due to some recent changes in the way Elixir handles debugging messages, Elixir 1.5 lets you take advantage of this functionality but only if you have Erlang 20 installed (at the time of this writing).
asdf
I would be somewhat remiss if I didn't mention asdf, as it is a pretty handy tool that lets you install more than just Elixir. Asdf is "an extendable version manager" and it supports Erlang, Elixir, Ruby, and more languages. In my experience you end up with a .tool-versions file in your code repositories where you're using the tool.
But that's a minor thing in my opinion. Overall, if I hadn't done kiex and kerl, I might have gone with asdf. The point is, "you do you". Pick what is most comfortable to you.
Option 1: Installing Elixir with Kiex and Kerl
I'm going to give you a step-by-step overview of how to install Elixir with kiex and kerl.
If you're used to using Ruby in your day job, you've probably come to appreciate the Ruby ecosystem of tools to get setup and running - bundler and rvm (or chruby or rbenv depending on your preferences).
But I'm used to RVM and other environment managers - where is the RVM for Elixir?
It turns out there's a few options for Elixir. I ended up originally using Kerl and Kiex. But now I use asdf as I find it's much simpler to get up and running. Since kiex and kerl are more complicated I'll walk you through them below. Here is how I installed them on my Ubuntu desktop and Mac OSX laptop.
Step 1 - Installing Kiex
Kiex is like RVM in that it allows you to switch between different Elixir versions and build them. Below is a set of instructions you enter at the command line.
$ curl -sSL https://raw.githubusercontent.com/taylor/kiex/master/install | bash -s
# In your .bashrc (or .zshrc if you use z shell) file, add the following line:
[[ -s "$HOME/.kiex/scripts/kiex" ]] && source "$HOME/.kiex/scripts/kiex"Step 2 - Installing Kerl, Elixir and Erlang
Because Elixir runs on top of Erlang, you need a way to build and install Erlang/OTP instances.
Below is a set of instructions you enter at the command line.
$ mkdir ~/.kerl
$ cd ~/.kerl
$ curl -O https://raw.githubusercontent.com/yrashk/kerl/master/kerl
$ chmod a+x kerl
$ kerl list releases
$ kiex list known
#can now use elixir
$ kiex install 1.5.2
$ kiex use 1.5.2
$ mkdir ~/erlang_install/20.0
$ kerl build 20.0 20.0
$ kerl install 20.0 ~/erlang_install/20.0You can activate this installation running the following command:
$ . ~/erlang_install/20.0/activateIn .bashrc (or .zshrc if you use z shell), add the following:
$ . ~/erlang_install/20.0/activateLater on, you can leave the installation by typing: kerl_deactivate
You can delete a build with kerl delete build 20.0.
Source: https://github.com/yrashk/kerl{:target="_blank"} - follow instructions and add export PATH="$PATH:$HOME/.kerl"
to .bashrc (or .zshrc or any other .rc file)
Troubleshooting
If you get a debug message such as:
Kiex sourcing line not found in ~/.bashrc, ~/.bash_profile, ~/.profile, ~/.zshrc, or ~/.zsh_profileAdd the following to your shell's config file (.bashrc/.zshrc/.cshrc):
[[ -s "$HOME/.kiex/scripts/kiex" ]] && source "$HOME/.kiex/scripts/kiex"Other useful commands
kerl list installations
erl versionerl version will list the Erlang version, you will see something like: Erlang (SMP,ASYNC_THREADS,HIPE) (BEAM) emulator version 5.8.3
kerl list installations will list the Erlang/OTP builds you installed.
Option 2: Installing Elixir with asdf
The other option is to install Elixir with asdf.
In terms of version numbers for Elixr and Erlang, version numbers should be the ones you want to use. Here I do it with the latest ones available at the moment of writing.
Anyway, if you intend to work with several versions of erlang or elixir at the same time, or you are tied to a specific version, you will need to compile it yourself. Then asdf is your best friend.
Step 1 - On Linux, install needed system packages
On Linux, you may have to install the following packages if you don't have them already.
Fedora
$ sudo dnf install make automake gcc gcc-c++ kernel-devel \
git wget openssl-devel ncurses-devel wxBase3 wxGTK3-devel m4Ubuntu
$ sudo apt-get install build-essential git wget libssl-dev \
libreadline-dev libncurses5-dev zlib1g-dev m4 curl wx-common libwxgtk3.0-dev autoconfStep 1a - On MacOSX, install needed system packages (via homebrew)
coreutils automake autoconf openssl libyaml readline libxslt libtool unixodbcStep 2 - Install asdf and its plugins
asdf lives in https://github.com/asdf-vm/asdf
Follow its installation instructions, which at the moment of writing were:
$ git clone https://github.com/asdf-vm/asdf.git ~/.asdf --branch v0.4.3For Ubuntu, other linux distros, or MacOSX
$ echo '. $HOME/.asdf/asdf.sh' >> ~/.bashrc
$ echo '. $HOME/.asdf/completions/asdf.bash' >> ~/.bashrcIf you're using Zsh shell, use these lines
$ echo -e '\n. $HOME/.asdf/asdf.sh' >> ~/.zshrc
$ echo -e '\n. $HOME/.asdf/completions/asdf.bash' >> ~/.zshrcStep 2a - On a new terminal, install Erlang and Elixir plugins:
$ asdf plugin-add erlang https://github.com/asdf-vm/asdf-erlang.git
$ asdf plugin-add elixir https://github.com/asdf-vm/asdf-elixir.gitStep 3 - Install Erlang and Elixir
$ asdf install erlang 20.2
$ asdf install elixir 1.6.4-otp-20Then set them as the global version:
$ asdf global erlang 20.2
$ asdf global elixir 1.6.4-otp-20Now you can open a new terminal and try erl:
$ erl
Erlang/OTP 20 [erts-9.0] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:10] [hipe] [kernel-poll:false]
Eshell V9.0 (abort with ^G)
1>Or start Erlang Observer by erl -s observer start.
And you can try 'iex':
$ iex
Erlang/OTP 20 [erts-9.0] [source] [64-bit] [smp:4:4] [ds:4:4:10] [async-threads:10] [hipe] [kernel-poll:false]
Interactive Elixir (1.5.0) - press Ctrl+C to exit (type h() ENTER for help)
iex(1)>Use asdf .tool-versions file to manage which version is active on each of your projects.
Enjoy!
Summary
As I said before, 50% of the battle in getting started with learning a new technology stack is getting setup with the right tooling. It's more productive and more fun to get started the right way.
The tools are always changing in the programming landscape, so if you find a cool tool you like, I do hope you'll share it with me so I can keep this guide updated for others as well as yourself!
Programming Terminology
Zen Masters and Adopting the Functional Mind
So let me tell you a story.1
Once, a long time ago, there was a wise Zen master. People from far and near would seek his counsel and ask for his wisdom. Many would come and ask him to teach them, enlighten them in the way of Zen. He seldom turned any away. One day an important man, a man used to command and obedience came to visit the master. "I have come today to ask you to teach me about Zen. Open my mind to enlightenment." The tone of the important man’s voice was one used to getting his own way. The Zen master smiled and said that they should discuss the matter over a cup of tea. When the tea was served the master poured his visitor a cup. He poured and he poured and the tea rose to the rim and began to spill over the table and finally onto the robes of the wealthy man. Finally the visitor shouted, "Enough. You are spilling the tea all over. Can’t you see the cup is full?" The master stopped pouring and smiled at his guest. "You are like this tea cup, so full that nothing more can be added. Come back to me when the cup is empty. Come back to me with an empty mind."
Learning Functional Programming Meant I Had to Let Go of the Object Oriented Mind
In Elixir, there is no such thing as "objects". There's no such thing as "classes". Most importantly, you'll hear a phrase "data is immutable".
This means that values in a certain memory location don't change. Often, you will see something like:
v = 2This is referred to as "binding" the value 2 to v. If you then did v = 3, this simply points v to a memory location that contains the value 3. The memory location that contains the value 2 still exists. That's why you refer to this operation as "rebinding the variable v to the value 3" instead of "assigning 3 to v" the way you do in object oriented languages.
From a programming standpoint, now both 2 and 3 are in memory until they are garbage collected.
How This Immutable Thing Relates to Elixir Processes and "Let It Crash"
If you hang around the Elixir community long enough, you'll hear the phrase "let it crash", meaning to let a process (containing data) just crash if an unexpected error happens. A process never has access to another process's data (and hence state), and so you don't have to worry that losing one process will affect behavior or data in another process. It's a recipe for a more stable system.
In object-oriented languages (like Java), where data can be mutated across threads, one thread can be updating while another can be reading from a data store, and so you need to worry about "protecting" state during concurrent operations.
The beauty and implication of the "rebinding" of the variable v, is that you have a guarantee that your data in a memory location won't change. Said another way, the "data is immutable".
Object-Oriented vs Functional
As I said before, one thing that you should be aware of right off the bat is that you're going to have to let go of your old notions of programming via object orientation. You'll see what I mean by that as we look at more of the Elixir language. For now, let's look at the first syntactical difference - the lack of classes.
Modules vs Classes
If you're coming from the Ruby world or some other object-oriented paradigm like Java, you may be used to dealing with the concept of classes. In Elixir, there's no such thing as a class. Instead Elixir gives you a module, which is a way to group functions together.
The other interesting implication of not having classes is that there's no such thing as "an instance of a class", or in this case "an instance of a module". You always call functions with the following syntax of ModuleName.function_name(arg1, arg2, ...).
Below is an example of a Calculator module with an add function.
defmodule Calculator do
def add(x, y) do
x + y
end
endIn a working Elixir program, you might have the Calculator perform some work with the following code:
Calculator.add(2,3)
#=> 5Functions: Input X, Output Y
Now that you've gotten a taste of Elixir modules and functions, I want to introduce one more analogy to help you wrap your head around the concept of functional programming. If you've ever taken an algebra class, you might be used to hearing about functions such as "f of x" (denoted f(x) for short).
You might have seen things like y = f(x) = x + 2 which means f(x) (or y) is the result of adding 2 to every input x. And that's simply how Elixir operates - you take some data, transform it via a function, and voila, you have a new result, or a new piece of data to operate on.
If you haven't taken algebra before, then you can think of it as a magician putting something into a hat (say a feather), and then pulling something else out of it, like a rabbit. One thing went in, and another came out.
Goodbye Inheritance
If you're used to Ruby, you might be used to seeing inherited classes like the Dog class.
class Mammal
def backbone?
true
end
end
class Dog < Mammal
endThere's no such thing as inheritance in Elixir. You just have modules that contain functions to operate on data.
Immutability
The other sticking point about Elixir that makes it different from an object-oriented language like Ruby is that data is immutable. In fact, hang around in the Elixir community long enough, and you'll hear the word "immutability" thrown around a lot.
I already gave an explanation above, so I won't rehash it. But to give it to you in the simplest terms, "data is immutable" means we never change data in memory, we only make copies of the data and transform it as necessary. The practical implication of this is that we don't hold state in variables.
How do you do state?
This of course begs the question, then "how do you do state"? We'll look at that in upcoming sections. For now, it's sufficient to say that Elixir lets you hold state via a process mechanism. And it gives you tools like GenServer to help you do it.
Summary
It might take a little while for you to "empty your cup", but hopefully the upcoming quizzes and projects will help you wrap your head around Elixir and functional programming concepts.
The Enum Module: The Answer To Ruby's Enumerable
Everyone Loves the Count
When I was a little boy, I used to watch Sesame Street. The show had this character called Count von Count, or simply, The Count.
His job on the show was to teach kids about simple mathematical concepts like counting. Watching him made counting and other mathematical concepts entertaining and fun to apply.
But then I grew up and discovered the Enumerable module...
As a self-taught web programmer, my first language was Ruby, via learning Ruby on Rails. One thing that was new to me was the the Enumerable module and its methods. As I got used to it, I found the Enumerable module quite beautiful as it enabled me to easily and elegantly operate on array collections. JavaScript has similar methods and I'd be willing to be other object-oriented languages do as well.
In fact, if type "enumerable" into Google, I get the definition "able to be counted by one-to-one correspondence with the set of all positive integers."
In fact, Ruby's Enumerable module does feel like it's designed to operate on a list of integers (or other "objects"). It became such a part of my toolset what I was hoping Elixir had one...
Introducing Enum...
Fortunately, Jose Valim, the creator of Elixir, was formerly a Ruby language programmer. So I'm betting he too appreciated the Enumerable module. And hence, we have the Enum module in Elixir.
Like the Enumerable module in Ruby, Elixir also provides us with the Enum module to work with collections. Typically, you'll find yourself operating on lists and maps.
Lists look a lot like arrays in Ruby, but we'll stick with the Elixir way of calling them lists.
Useful Enum Module Methods
Now let's go over some useful Enum module methods. These are methods I find myself using over and over again in real world applications.
Enum#at
Let's suppose we have the following list of integers bound to m.
m = [2, 1, 4]What happens if we wanted to get the second element? In Ruby, you might do something like m[1]. You'll find if you try that in Elixir you'll get an error. Instead, you can use the at method of the Enum module as follows.
Enum.at(m, 1)
# => 1Enum#reduce
If you're used to Ruby's inject operator, you've probably seen things like:
a = [1, 2, 3]
a.inject { |sum, x| sum + x }
# => 6The reduce method of the Enum module operates much the same way. Like all things in Elixir the major syntacitcal difference is that you call it using the module name follwed by the method name as follows:
Enum.reduce([1, 2, 3], fn(x, accumulator) -> x + accumulator end)
# => 6 is the sum of 1, 2, and 3Note that just like in Ruby's inject method, the Enum#reduce method has an accumulator to hold the results of your computations.
Enum#map
Like Ruby, Elixir also gives you a map operator.
In Ruby:
a = [1, 2, 3]
a.map { |x| x * 2}
# => [2, 4, 6]In Elixir:
Enum.map([1, 2, 3], fn(x) -> x * 2 end)
# => [2, 4, 6]Enum#filter
Ruby gives you a handy select method to "filter" elements you want from an array. Below we select all elements from the array for which the condition holds true.
[1, 2, 3].select { |x| x%2 == 0}
#=> [2]The Enum#filter method operates much the same way.
Enum.filter([1, 2, 3], fn(x) -> rem(x, 2) == 0 end)
#=> [2]Enum#reject
Ruby's converse of the select method is the reject method.
[1, 2, 3].reject { |x| x%2 == 0}
#=> [1, 3]Enum.reject([1, 2, 3], fn(x) -> rem(x, 2) == 0 end)
#=> [1, 3]Enum#all?
Ruby also has an all? method which is extremely similar to Elixir's. Or perhaps I should say it's the other way around.
In any case, the all? method returns true if all the elements meet the condition.
[1, 2, 3].all? { |x| x%2==0 }
# => falseHopefully by now you're seeing a common pattern. There are parts of Elixir's syntax that borrow beautifully from Ruby (or should I say shamelessly copy?)
Enum.all?([1, 2, 3], fn(x) -> rem(x,2) == 0 end)
# => falseEnum#any?
Ruby also has an any? method to check if any element in a collection meets a particular condition.
[1, 2, 3].any? { |x| x%2==0 }
# => trueElixir also has an any? method.
Enum.any?([1, 2, 3], fn(x) -> rem(x,2) == 0 end)
# => trueEnum#to_list with a range
Sometimes you want to generate a long list of numbers but you don't want to type it all out. The solution is to pass a range into Enum's to_list method and let it do the work for you.
Enum.to_list(1..3)
# => [1, 2, 3]Enum#count
Sometimes you just want to know the length of a list. The count method can easily do that for you.
Enum.count [1, 2, 3]
# => 3Summary
Like Sesame Street's, The Count, the Enum module makes learning fun. The Enum module gives you quite a few useful methods for operating on data. I encourage you to read the documentation and discover even more methods. An upcoming quiz will ask you to make use of Enum's methods, so stay tuned!
The List Module
The Linked List Data Structure and the CSV Reporter
I did study Computer Science in university, and one thing they covered was the linked list data structure. In Ruby (and other object-oriented languages), you basically get these for free through arrays.
Instead of arrays, Elixir has a concept called "lists". They look very much like arrays and behave much the same way. They are an Elixir version of linked lists.
Making a YouTube CSV Reporter
While building my first simple production application, I built an Elixir application that pulled down data from YouTube and turned it into a CSV (comma-separate value) report. It pulled down publicly available metrics and emailed them to a business unit that needed them for reporting purposes.
As I built this application, I found myself operating on lists of data in Elixir. In fact, I'd say all my real world application usage of Elixir involved Lists in some way. So it's definitely worth familiarizing yourself with the List module in Elixir.
Useful List Module Methods
Like the Array module in Ruby, Elixir also provides us with a module to work with lists. Typically, you'll find yourself operating on lists and maps.
Lists look a lot like arrays in Ruby, but we'll stick with the Elixir way of calling them lists.
List.first
Here is the Ruby syntax for calling first on an array.
a = [1, 2, 3]
a.first
# => 1And here is the Elixir syntax for calling first on a list.
a = [1, 2, 3]
List.first(a)
# => 1List.last
Here is the Ruby syntax for calling last on an array.
a = [1, 2, 3]
a.last
# => 3And here is the Elixir syntax for calling last on a list.
a = [1, 2, 3]
List.last(a)
# => 1List.flatten
Ruby gives you a flatten method for arrays as follows.
a = [[1,2], [[3], 4]]
a.flatten
# => [1, 2, 3, 4]And so does Elixir.
a = [[1,2], [[3], 4]]
List.flatten(a)
# => [1, 2, 3, 4]List.foldl
Off the top of my head, I don't know of a Ruby equivalent for Elixir's foldl method.
But the foldl method uses a function to reduce the list from the left. Below is a code snippet with an explanation of how the list is being folded.
a = [3, 2, 1]
List.foldl(a, 0, fn(elem, accumulator) -> elem - accumulator end)
# => 2
# because 3-0 = 3, 2 - 3 = -1, and 1 - (-1) = 2List.insert_at
Elixir's List#insert_at function is probably closest to Ruby's Array#insert function.
Here is how you insert into an array at a particular index value. We insert the value 5 at index 1.
a = [1, 2, 3]
a.insert(1, 5)
# => [1, 5, 2, 3]Here is the Elixir equivalent.
a = [1, 2, 3]
List.insert_at(a, 1, 5)
# => [1, 5, 2, 3]List.delete_at
When deleting an element out of a list in Elixir, you simply specify the index number at which you wish to delete the element.
a = [1, 5, 2, 3]
List.delete_at(a, 1)
# => [1, 5, 2, 3]++ and - -
You can add elements to a list in Elixir with the ++ operator and remove them with the - - operator.
[1, 2] ++ [-1, 5]
# => [1, 2, -1, 5]
t = [1, 2, -1, 5]
t -- [1]
# => [2, -1, 5]Summary
Lists are one of the most common data structures used in day to day Elixir development in my experience. It's worth knowing the methods in that module as you will be using them frequently.
The Map Module
The Dictionary
If you've ever used Webster's Dictionary, you know you look up a word, say "aardvark", and flip through the pages to locate the definition. If you think of "aardvark" as a key of sorts, and then its corresponding definition as a "value", you'll have an analogy to the dictionary abstract data type.
Basically, you use a key to access a value. The first important property of a dictionary are that the keys are hashabale and equally comparable, which is often why keys are letters or numbers. The second important property is that the entries appear in no particular order (which is a contrast to Webster's Dictionary).2
The Ruby language has an implementation of the dictionary data type called a Hash. So do other object-oriented languages like Java.
But what about Elixir?
Elixir has an implementation called a map. In fact, when I was building a reporting tool that emailed comma-separated value text files, I used the Map module quite a bit. As you work with Elixir, you'll likely find that you use the Map module quite a bit as you transform and iterate over your data.
So let's dive in to some useful map methods.
Useful Map Module Methods
Besides lists, the other data structure you'll encounter frequently in Elixir are maps. I have found myself using them in everything I do.
Map.get
So Map's get method lets you fetch a value by key. It's very similar to the fetch method for a hash in Ruby.
m = %{:b => 2, "c" => 3, :d => 4}
Map.get(m, :b)
#=> 2
Map.get(m, :c)
#=> nil
Map.get(m, "c")
#=> 3You'll notice from the above code, you have to be very specific about which key you use to fetch a value.
Map.put
Map's put method is for putting a value associated with a key in a map. It can be used for adding new key and value pairs or updating old ones.
m = %{:b => 2, :c => 3}
Map.put(m, :c, 5)
#=> %{b: 2, c: 5}Elixir's built-in syntax for updating maps
One cool trick I've learned from reading this blog post is how to do updating one or more map key values using a special syntax
m = %{:b => 2, :c => 3}
%{m | :b => 4, :c => 5}
#=> %{b: 4, c: 5}Map.has_key?
Similar to a Ruby hash, Elixir gives you the ability to check if a given key is in a map.
m = %{:b => 2, :c => 3}
Map.has_key?(m, :b)
#=> trueMap.keys
Using Map's keys function, you can get a list of keys only. This is analagous to Ruby's keys function for Hash.
m = %{:b => 2, :c => 3}
Map.keys(m)
#=> [:b, :c]Map.values
Using Map's values function, you can get a list of values only.
m = %{:b => 2, :c => 3}
Map.values(m)
#=> [2, 3]Map.replace
Map's replace is handy in that it will alter the value associated with a key, but only if that key exists.
m = %{:b => 2, :c => 3}
Map.replace(m, :b , 2)
#=> %{b: 4, c: 3}Map.merge
Map's merge is another handy data transformation function I often find myself using to merge 2 maps together.
m = %{:b => 2, :c => 3}
Map.merge(m, %{d: 5})
#=> %{b: 2, c: 3, d: 5}Map.drop
Map's drop is good for removing keys from the list.
m = %{:b => 2, :c => 3}
Map.drop(m, [:c])
#=> %{b: 2}Map.to_list
Interestingly enough, I recently found out you could convert maps to a list of tuples.
m = %{:b => 2, :c => 3}
t = Map.to_list(m)
#=> [b: 2, c: 3]
List.first t
#=> {:b, 2}Map.update
I haven't used Map's update too much, but it's pretty handy for updating key values in a map. In the below example, code I used an initial value of "-1", which is what the value of "a" would have been if it had not already existed in the map. Instead, the value of a is set to "1 times 3", which is 3.
m = %{"a" => 1, "b" => 2}
Map.update(m, "a", -1, &(&1 * 3))
#=> %{"a" => 3, "b" => 2}A word on nested maps
One thing I found that was hard to deal with was when I wanted to drop keys out of nested maps. To that end, I built a hex package called nested_filter to handle this. It's a bit complicated at this point, but someone was kind enough to review it and if you go through the commit history you can see how it evolved.
We'll probably come back to this later when we discuss anonymous functions, but I wanted it to mention it now in case you wanted to take a look.
Summary
The Map module is something you'll use over and over again. It's something I used in my first Elixir application for CSV reports and it's something I still use in my production applications today.
Footnotes
Conditionals in Elixir
Conditional Control Flow Structures
My Overreliance on Cond
When I first started with Elixir I tended to rely on conditionals much more than I would care to admit. This is because I wasn't quite fluent with a concept called pattern matching, which is something we'll talk about in upcoming course modules.
I tended to do things like:
defmodule NestedFilter do
def drop_by_key(map, filter_keys) do
cond do
is_nested_map?(map) ->
new_map = map
|> Enum.reduce(%{}, fn({key, val}, acc) ->
Map.put(acc, key, drop_by_key(val, filter_keys)) end)
Map.drop(new_map, filter_keys)
is_map(map) ->
Map.drop(map, filter_keys)
true ->
map
end
end
endToday I would cringe at that kind of code. A better improvement would have been to use a case statement (and an even better one would be the use of pattern matching). And that leads us to the topic of conditionals. We're going to talk about cond, case, and if.
Cond
Coming from Ruby, cond reminds me of the if/elsif/end structure in Ruby. In other languages it's equivalent to an if/else if type of control flow.
Its use case is to match on conditions. In the example below, you can see you hit the "catch all" true condition, which is like hitting the "else" portion of an if/else conditional flow in Ruby.
defmodule Hello do
def hello(msg) do
cond do
msg == "world" ->
"hello world"
msg == "no" ->
"heck no"
true ->
"you hit the catch all"
end
end
end
#=> "you hit the catch all"Case
In production ready code, I've seen the case conditional used quite a bit, especially when pattern matching against success and error tuples. Below is an example snippet in the context of a Phoenix controller. The hypothetical "DoSomething" module does something with the incoming params map and then the with_params method returns a success or error tuple.
From there, we let the phoenix controller decide what to render.
defmodule App.YourController do
def show(conn, params = %{id: id}) do
case DoSomething.with_params(params) do
{:ok, message} ->
conn
|> put_status(:ok)
|> render("show.json", message: message)
{:error, _} ->
conn
|> put_status(:unprocessable_entity)
|> render("error.json", message: "unprocessable entity")
_ ->
conn
|> put_status(:unprocessable_entity)
|> render("error.json", message: "unprocessable entity")
end
end
endThe underscore _ in the case statement acts as a catchall, much like the true in the cond statement.
If
The interesting thing to note about Elixir's if statement is that unlike Ruby, there's no concept of elsif. So you won't run into a lot of nested if statements (hopefully) unlike in some of the Ruby startup code bases I've seen.
t = [1, 2, 3]
if is_list(t) do
IO.inspect "it's a list!"
else
IO.inspect "it's NOT a list!"
end
#=> "it's a list!"You can do nested if statements, but it's ugly and I've never seen it any good codebase. So please do avoid it, although I will show it to you here for completeness sake.
t = 1
if is_list(t) do
IO.inspect "it's a list!"
else
if is_integer(t) do
IO.inspect "it's an int!"
else
IO.inspect "it's not an int!"
end
IO.inspect "it's NOT a list!"
end
#=> "it's an int!"
#=> "it's NOT a list!"Unless
Elixir's unless statement follows the same pattern as its if statement.
t = 1
unless is_list(t) do
IO.inspect "it's NOT a list!"
else
IO.inspect "it's a list!"
end
#=> "it's NOT a list!"Summary
As a general rule of thumb, a case statement is more idiomatic than cond, but cond has its uses. It's rare to see if statements in Elixir, although it does happen.
Handy Keywords For Working With Modules and Anonymous Functions in Elixir
The 2 Hardest Problems in Computer Science
There are only two hard things in Computer Science: cache invalidation and naming things. -- Phil Karlton
So the quote from Phil Karlton I pulled from Martin Fowler's website.3
And the longer I kept programming, the more I realized that Phil was right. Naming things - whether it be variables, classes, or files - is really hard. I can recall in my own object-oriented programming, how taxing it could be trying to name classes and methods in accordance with the problem domain I was looking at.
Unfortunately, functional programming with Elixir can't solve this problem. However, there are tricks Elixir gives you to save you from typing your module names over and over.
When working with the Elixir frameworks such as Phoenix, you'll find these tricks useful especially when dealing with the namespacing of modules.
In this section, we're going to talk about handy keywords when working with Modules as well as Anonymous Functions in Elixir.
Alias and Import
Alias and import are two of the most common features of Elixir you'll most likely be using when you first start using Elixir, especially if you're using it in a web application (at least in my experience).
Alias
I think of the alias command as a shortcut to save you from typing. In actuality, you can do more with it.
For example, suppose you have the following module(s) defined.
defmodule Project.Calculator.Adder do
def add(a,b), do: a + b
def add(a, b, c), do: a + b + c
end
defmodule Project.Machine do
alias Project.Calculator.Adder
# we can call Adder.add thanks to alias
def add_two(a, b), do: Adder.add(a, b)
end
defmodule Project.Machine2 do
alias Project.Calculator.Adder, as: C
def add_two(a, b), do: C.add(a, b)
endWe could have also aliased Project.Calculator.Adder as something else entirely with the as option as shown in the Project.Machine2 module.
The other thing you can do is alias more than one module in the same line. In the below example, I am aliasing the Project.Calculator.Arithmetic modules and the Project.Calculator.Subtracter modules in one line.
defmodule Project.Calculator.Arithmetic do
def hello, do: "hello"
end
defmodule Project.Calculator.Subtracter do
def subtract(a, b), do: a - b
end
defmodule Project.Calculator.Adder do
alias Project.Calculator.{Arithmetic, Subtracter}
endTry the source code for yourself by copying and pasting it in the iex shell.
Import
I think of import as a way to easily use functions from other modules without having to type out any part of the module name (unlike alias).
Here's how that would look with our Calculator example.
defmodule Project.Calculator.Adder do
def add(a,b), do: a + b
def add(a, b, c), do: a + b + c
end
defmodule Project.Machine do
import Project.Calculator.Adder
# import Project.Calculator.Adder, only: [add: 2, add: 3]
# we can call Adder.add as add thanks to import
def add_two(a, b), do: add(a, b)
def add_three(a, b, c), do: add(a, b, c)
endInterestingly enough, I recently learned that import has an only option to let you only import macros or functions. You can also specify specific functions that get called as well. You'll notice the numbers 2 and 3 in the code above. This tells Elixir to only import the function that takes 2 arguments or 3 arguments, respectively.
You can see this in the commented line in the previous code block example with Project.Machine.
Module Attributes
If you're used to constants in Ruby, you might be wondering what is the best way to handle those in Elixir. So far, I've found 2 good ways, one is through using private functions (defp my_function, do: "private_constant") and module attributes.
Let's go back to our calculator example and see how we can use them.
defmodule Project.Calculator.Adder do
@moduledoc """
Provides adding functions for a calculator
"""
# let's have a version constant for this module to define its version
@version "1.0"
@doc """
Calculate the sum of 2 numbers
"""
def add(a,b), do: a + b
@doc """
Calculate the sum of 3 numbers
"""
def add(a, b, c), do: a + b + c
@doc """
Return the version constant
"""
def version, do: @version
endThere's a bit to unpack from the above sample code (which you can paste into your iex shell and try out).
@moduledoc and @doc are called reserved attributes in Elixir and provide module documentation and function or macro documentation, respectively. We haven't talked about macros yet, but we will in an upcoming chapter. For now, you can think of macros as a part of Elixir's metaprogramming facilities.
@version is a custom module attribute that we defined to hold the "version" information for a module. We could have defined it to be a list or even a tuple.
Typically, Elixir developers use it as a temporary storage facility in a module (e.g., like a constant).
Anonymous Functions
One cool feature I like about Elixir is its ability to handle anonymous functions as first class citizens.
An anonymous function can be defined as follows.
# Let's define an anonymous function to compute the area of a triangle and bind it to area_triangle
area_triangle = fn(base, height) ->
0.5 * base * height
end
# Let's define an anonymous function and adds the value of x to the value of whatever is computed by the anonymous function passed in via the area_func parameter in add_to_func
add_to_func = fn(x, area_func) ->
x + area_func.(2, 1)
end
add_to_func.(2, area_triangle)
# => 3.0
# It's 3.0 because area_triangle computes a value of 1.0Summary
Naming things is still a hard problem whether you're doing functional programming or object-oriented programming. Fortunately, Elixir does give you tools to at least save you some typing when you are constructing module namespaces and re-using module functionality.
Footnotes
A Word On Types
The First Thing I Do When Getting Started With a Programming Language
Every program I've ever written comes down to dealing with data in some way. One of the first things I do when learning a new programming language is to get a sense of the data types available to me. For example, when I was doing Ruby on Rails work, and wanted to create database columns with numbers, I wanted to know how the Rails commands that auto-generated database table creation commands mapped to a database's data types.
It's also important to understand whether you're dealing with a statically-typed language like Java, which means you have to declare upfront what type of variable it is (e.g., int a = 2;, which means a holds an integer), or a dynamically typed language like Ruby where variables can hold any kind of data.
Like Ruby, Elixir is a dynamically typed language. Unlike Erlang, Elixir will allow you to rebind a value to a variable. That's why you can do:
a = [1, 2, 3]
a = 2So now it's time to take a look at the data types available to you in Elixir.
Integers and Floats
Elixir has integers and floats as its primary way of representing numbers. And it has the Integer and Float modules with functions to allow you to work with those types.
Arithmetic
One nice feature Ruby gives you is the "%" or modulus operator for finding the remainder of a division operation.
Elixir gives you this through the "rem" function.
rem(9, 3)
#=> 0
rem(6, 4)
#=> 2Boolean
Elixir gives you true and false as boolean values. Interesting enough, they are equivalent to their respective atoms.
true == :true
#=> true
is_atom(true)
#=> true
false == :false
#=> falseAtoms
You've seen atom keys throughout this lesson in the various example map structures we've shown.
Elixir has a concept called atoms. An atom's name is its value. If you've worked with the Ruby programming language, you'll find they are analagous to Ruby symbols. If you're coming from a language like Java or C++, I'm not sure there's an equivalent analogy, so for clarity's sake I'll show a code example.
m = %{:a => 1, :b => 2}You can see in the above code example that :a and :b are both atom keys in a map.
Strings
Strings in Elixir are UTF-8 encoded and you use double quotes to represent them.
Note: single quotes denote character lists and mean something else entirely.
Lists
Lists are analogous to arrays in Ruby or other object-oriented languages like Java. We've seen them throughout the course in various examples.
# an example list
a = [1, 2, 3]Tuples
One interesting type that you don't have an analogy for as a Ruby programmer is the tuple. You define a tuple with curly braces. Tuples can hold any kind of value and store data contiguously in memory.
What does this mean practically? It means you can use the Kernel#elem method to get a tuple element by its index is a fairly fast operation.
tuple = {:ok, 1, :msg, "abc"}
elem(tuple, 2)
#=> :msgSummary
Ok, so now you've been given a crash course on the types available to you in Elixir. Coming up, we'll be looking at comprehensions and some other concepts before we head into your first project.
Elixir's Comprehensions (Not Loops)
The Misuse of Elixir's Comprehensions
So having some minor experience with Java and other object-oriented languages, I was curious if Elixir had a "for loop", "while loop" or some other kind of looping construct.
And when I found the "for" keyword in Elixir, I thought "finally". And of course I tried to use it like a "for loop" in an object-oriented language where I stored a piece of stateful information in a variable and expected it to be available later....Oops. I think I was trying to implement a version of the Traveling Salesman Algorithm.
The Purpose of Comprehensions
If you recall the Enum module in Elixir, there were sets of operations that allowed you to loop over a list/collection, and transform the list into another one.
Comprehensions are simply another way of doing this. The Elixir documentation refers to comprehensions as "syntactic sugar" for such operations.
A Simple Example of a Comprehension
To get an idea of what comprehensions can do, let's look at a simple example.
for x <- [3, 4, 5], do: 2*x
# => [6, 8, 10]As a comparison, you could have done the above example with a map such as in the below example.
Enum.map([3, 4, 5], fn(x) -> 2*x end)
# => [6, 8, 10]Multiple Generators
In the above example comprehension x <- [3, 4, 5] is referred to as a generator. You can have multiple generators in a comprehension.
for x <- [3, 4, 5], y <- [1, 2], do: x + y
# => [4, 5, 5, 6, 6, 7]You can see what happened. First, 3+1 and 3+2 were computed. Then 4+1 and 4+2 were computed. Finally, 5+1 and 5+2 were computed.
Extracting Data Using Pattern Matching
You can also use comprehensions in to transform a keyword list (list of tuples) into a different data structure, such as a list. If you look closely at the code below, you'll notice you're pattern matching.
for {key, val} <- [{:a, 1}, {:b, 4}, {:d, 6}], do: key
# => [:a, :b, :d]Filtering in Comprehensions
If you recall from the article/video on Enum, there was a filter function that allowed you to select elements that met a certain condition. Comprehensions allow you to do this too. Look at the example below.
import Integer
for {key, val} <- [{:a, 1}, {:b, 4}, {:d, 5}], is_odd(val), do: key
# => [:a, :d]And with the above pattern matching and filtering mechanism provided to us by comprehensions, we select only the keys associated with odd values.
Into a Map
Let's be honest. Sometimes you don't want lists, you want a map. And you can have that with the handy :into option.
for {key, val} <- [{:a, 1}, {:b, 4}, {:d, 5}], into: %{}, do: {key, val}
# => %{a: 1, b: 4, d: 5}In actuality, you can apply :into to any structure in Elixir that implements what's known as the Collectable protocol. We are going to touch on protocols in an upcoming section, so I will hold off on defining them for now. Suffice it to say, you can pass in a list, map, or string into the :into option.
Summary
So hopefully you've gotten a good overview of what you can do with comprehensions. And the next time you see the for keyword in an Elixir program, think "comprehension" not "for loop".
Strings in Elixir
When IO.inspect Let Me Down With a Character List
So in other languages, sometimes you want to output the contents of an array to see what it contains. For example, in the Ruby programming language, if I have an array a = [8, 9, 10, 11], I can do the following.
a = [8, 9, 10, 11]
a.inspect
# => [8, 9, 10, 11]Notice how I can see the array contains 8, 9, 10, and 11.
When I started with Elixir, I found I could more or less do the same thing with IO.inspect. But one day, I was let down with a surprise. I did the following.
a = [8, 9, 10, 11]
IO.inspect a
# => '\b\t\n\v'WTF is going on?
But first, we need to talk about binaries
To answer that, we have to learn about binaries. A binary is simply a sequence of bytes in Elixir. And a byte is simply 8 bits. And in computer-ese, a bit is simply a 0 or 1.
Let's see how to represent a binary with actual code
Below is a code block that shows you how to represent a binary.
binary_example = <<65, 66, 68>>Now, the double angled brackets (<< >>) defines a new bitstring. Each bitstring is composed of many segments, each of which has a type. There are 9 types of segments that can be used in bitstrings including integer, float, utf8, utf16, and utf32.
What does this have to do with strings again?
Strings are a subset of binaries. Specifically, strings are a valid UTF-8 sequence of bytes. How do you know if you have a valid string on your hands? Fortunately, Elixir's String module gives you a way with the valid? method.
binary_example = <<65, 66, 68>>
String.valid? binary_example
#=> trueSingle versus double quotes
The other thing you'll notice when dealing with strings in Elixir is the double-quoted and single-quoted strings.
Properties of double-quoted strings.
Before we dive into what single-quoted strings are, let's talk about what you can do with double-quoted strings in Elixir. Here are the two most common use cases.
Common Use Case 1: Variable Interpolation
In some of the production-grade Phoenix web applications I've been writing, I've found variable interpolations in strings quite handy. For example, if I want to embed a dynamic link URL that changes depending on what "category" it is, I might do something as shown in the below code block.
category = "food"
url = "http://www.foodie.com/#{category}"If you're familiar with a dynamic object-oriented language like Ruby, then this style of interpolation might look quite familiar to you.
You can also think of variable interpolation as an alternative way to concatenate strings.
For example, this is the "regular" way to concatenate strings:
b = "world"
"hello " <> bBut you could also do it this way:
b = "world"
"hello #{b}"Common Use Case 2: Documentation
In Elixir modules, you'll often see strings used to document modules. Below is an example from a hex package I wrote called nested_filter.
@doc """
Take a (nested) map and filter out any keys with specified values in the
values_to_reject list.
"""
@spec drop_by_value(%{any => any}, [any]) :: %{any => any}
def drop_by_value(map, values_to_reject) when is_map(map) do
drop_by(map, fn (_, val) -> val in values_to_reject end)
endSingle-quoted strings are character lists
Remember from the paragraphs above how inspecting a list of integers produced the following?
a = [8, 9, 10, 11]
IO.inspect a
# => '\b\t\n\v'Each of those characters is a codepoint, or a character. Each codepoint is represented by what's known as a code unit, which refers to the number of bits an encoding uses. Examples of encodings include UTF-8 (8 bit encoding) and UTF-16 (16 bit encoding).
So when Elixir prints out a character list like the above example, it really prints out the UTF-8 codepoints that the character list of integers represents.
How do you avoid printing out the character representations?
Before I tell you, let me show you a really cool trick. Boot up an "iex" prompt and type h Inspect.Opts.
You should see something like:
Inspect.Opts
Defines the Inspect.Opts used by the Inspect protocol.
The following fields are available:
• :structs - when false, structs are not formatted by the inspect
protocol, they are instead printed as maps, defaults to true.
• :binaries - when :as_strings all binaries will be printed as strings,
non-printable bytes will be escaped.
When :as_binaries all binaries will be printed in bit syntax.
When the default :infer, the binary will be printed as a string if it is
printable, otherwise in bit syntax.
• :charlists - when :as_charlists all lists will be printed as char
lists, non-printable elements will be escaped.
When :as_lists all lists will be printed as lists.
When the default :infer, the list will be printed as a charlist if it is
printable, otherwise as list.
• :limit - limits the number of items that are printed for tuples,
bitstrings, maps, lists and any other collection of items. It does not
apply to strings nor charlists and defaults to 50.
• :printable_limit - limits the number of bytes that are printed for
strings and char lists. Defaults to 4096.
• :pretty - if set to true enables pretty printing, defaults to false.
• :width - defaults to 80 characters, used when pretty is true or when
printing to IO devices. Set to 0 to force each item to be printed on its
own line.
• :base - prints integers as :binary, :octal, :decimal, or :hex, defaults
to :decimal. When inspecting binaries any :base other than :decimal implies
binaries: :as_binaries.
• :safe - when false, failures while inspecting structs will be raised as
errors instead of being wrapped in the Inspect.Error exception. This is
useful when debugging failures and crashes for custom inspect
implementations
• :syntax_colors - when set to a keyword list of colors the output will
be colorized. The keys are types and the values are the colors to use for
each type. e.g. [number: :red, atom: :blue]. Types can include :number,
:atom, regex, :tuple, :map, :list, and :reset. Colors can be any
t:IO.ANSI.ansidata/0 as accepted by IO.ANSI.format/1.Notice the ":as_lists" argument you can pass to the ":charlists" option. The following code example illustrates this:
binary_example = [98, 101, 100]
IO.inspect binary_example
#=> 'bed'
IO.inspect binary_example, charlists: :as_lists
#=> [98, 101, 100]When you pass in the ":as_lists" argument, you get back a list of integers from calling IO.inspect.
Note: the :as_lists option is for Elixir >= 1.5. According to this stackoverflow post4, with Elixir < 1.4, pass "false" as an argument to the ":char_lists" option.
You previously saw this before in the discussion of double-quoted strings, but I'll include the example below again for convenience.
@doc """
Take a (nested) map and filter out any keys with specified values in the
values_to_reject list.
"""
@spec drop_by_value(%{any => any}, [any]) :: %{any => any}
def drop_by_value(map, values_to_reject) when is_map(map) do
drop_by(map, fn (_, val) -> val in values_to_reject end)
endHeredocs
Finally, no discussion of strings would be complete without at least mentioning Heredocs. Heredocs are multiline strings which are used to document code in Elixir (at least, that's the way I've mostly seen them).
@doc """
Output hello world message
"""
def hello_world, do: "hello world"Some Interesting Reference Links
These are some of the references I used when making this post.
- http://culttt.com/2016/03/21/working-strings-elixir/
- https://medium.com/@harry_dev/elixir-for-rubyists-charlists-binarys-strings-iolists-eeacf38db999
- https://www.bignerdranch.com/blog/elixir-and-io-lists-part-1-building-output-efficiently/
- https://www.bignerdranch.com/blog/elixir-and-io-lists-part-2-io-lists-in-phoenix/
What Open Source Taught Me About the Basics of Documentation In Elixir
Looking at Timex
When I first started learning about Elixir, one of the first open source libraries I came across was Timex{:target="_blank"}. Within that library, I came across the Types module{:target="_blank"}.
Within that library, I saw the following code...
defmodule Timex.Types do
# Date types
@type year :: Calendar.year
@type month :: Calendar.month
@type day :: Calendar.day
@type num_of_days :: 28..31
@type daynum :: 1..366
@type week_of_month :: 1..5
@type weekday :: 1..7
@type weeknum :: 1..53
# Time types
@type hour :: Calendar.hour
@type minute :: Calendar.minute
@type second :: Calendar.second
@type microsecond :: Calendar.microsecond
@type timestamp :: {megaseconds, seconds, microseconds }
@type megaseconds :: non_neg_integer
@type seconds :: non_neg_integer
@type microseconds :: non_neg_integer
# some code was left out for brevity...
endAnd I wondered what is this "@type" syntax?
The Philosophy of Documentation as a First Class Citizen
Before we get to the actual way to write documentation in Elixir, let's briefly dive into a phrase you'll often hear -- "documentation as a first class citizen." What does this mean? From Elixir's documentation itself{:target="_blank"}, it means "documentation should be easy to write and easy to read."
The Syntax for Writing Documentation - Markdown
The way to write documentation in Elixir is by using markdown syntax. There are plenty of tutorials such as this one by GitHub that cover this syntax, but I'll give you a quick overview to get started.
Markdown is simply a shorthand syntax that eventually gets parsed into HTML.
Headings
The pound sign (#) is used to create HTML heading tags. One pound sign is equivalent to an "h1" tag and six pounds signs is a "h6" tag.
Code blocks
You can use backticks (`) to specify blocks of code that will be prefaced with "pre" or "code" tags when converted to HTML.
defmodule DemoCode do def hello, do: "hello" end
Lists
Since markdown gets converted to HTML, you can have ordered and unordered lists.
Ordered Lists
For ordered lists, you use numbers followed by periods. For example:
- item 1
- item 2
- item 3
Unordered Lists
For unordered lists, you use pluses, asterisks, or hypens. For example:
- item 1
- item 2
- item 3
Basic Styling of Text
If you need to italicize text, use asterisks or single underscores. For example:
This text will be put into an tag.
You'll end up with html that looks like:
<em>This text will be put into an <em> tagExternal Hyperlinks
If you need to annotate a hyperlink in markdown, you use square brackets that enclose descriptive text surrounded by parentheses that contain the hyperlink.
It looks like the following:
[This link goes to my blog post on nested filter.](http://www.binarywebpark.com/nested-filter/)Ok, so now you have a brief overview of markdown. It's time to start documenting!
Documenting Your Elixir Code
Erlang has the notion of something called module attributes that applies in Elixir. In Elixir code, module attributes are often used to define constants or as a temporary storage holder for values to be used during code compilation.
When documenting Elixir code, you'll rely a lot on the reserved attributes "@moduledoc" and "@doc".
Documenting Modules
When documenting modules, you'll use the @moduledoc attribute. The following is an example.
defmodule HelloWorld do
@moduledoc """
This is the HelloWorld module
"""
def hello_world, do: "hello_world"
endWhat if you didn't wish to document this module?
Then you could set @moduledoc to false. So it would look like this:
defmodule HelloWorld do
@moduledoc false
def hello_world, do: "hello_world"
endDocumenting Modules With Style
Believe it or not, there is a proper style to document modules via this community style guide{:target="_blank"}. Right now Elixir is pretty new, so this could change, but I think it serves as good guidance for now.
The basic tenets are:
- The @moduledoc attribute should be included right after the "defmodule" line.
- Separate the @moduledoc documentation with a blank line between the end of the documentation and new code.
- Be sure to use heredocs for the description text for @moduledoc.
Documenting Functions
When documenting functions, you'll use the @doc attribute. We now document the function in the HelloWorld module in the following example.
defmodule HelloWorld do
@moduledoc """
This is the HelloWorld module
"""
@doc """
Says hello_world
Returns "hello_world"
## Examples
iex> HelloWorld.hello_world
hello_world
"""
def hello_world, do: "hello_world"
endWhat if you didn't want to document this function? Similar to module documentation, you can set @doc to false.
A Word on Documenting Private Functions
So the big deal here is that you can't. You'll get a stern warning from Elixir and your documentation description will be ignored.
Typespecs
Remember how I mentioned the Timex library?
Even though Elixir is a dynamically typed language, it still gives you functionality for documenting typed function signatures and declaring custom types.
Declaring custom types is what the Types module in the Timex library did.
@type attribute
To understand the @type attribute for declaring custom data types, let's look at a portion of the Timex.Types module again.
defmodule Timex.Types do
# Time types
@type timestamp :: {megaseconds, seconds, microseconds }
@type megaseconds :: non_neg_integer
@type seconds :: non_neg_integer
@type microseconds :: non_neg_integer
# some code was left out for brevity...
endNotice the types megaseconds, seconds, and microseconds. They are defined as a "non_neg_integer". Now a "non_neg_integer" is a built-in type specification. You'll find that Elixir steals a lot of its built-in type specifications from Erlang and expresses it the same way.
Now notice the timestamp type. This is the custom day type that is defined. It is a tuple composed of the built-in types.
Basic Types in Elixir Documentation
I'm printing out the basic types in Elixir here as a convenience. I pulled it from the Hex docs{:target="_blank"}.
type :: any() # the top type, the set of all terms
:: none() # the bottom type, contains no terms
:: atom()
:: map() # any map
:: pid() # process identifier
:: port()
:: reference()
:: struct() # any struct
:: tuple() # tuple of any size
:: ## Numbers
:: float()
:: integer()
:: neg_integer() # ..., -3, -2, -1
:: non_neg_integer() # 0, 1, 2, 3, ...
:: pos_integer() # 1, 2, 3, ...
:: ## Lists
:: list(type) # proper list ([]-terminated)
:: nonempty_list(type) # non-empty proper list
:: maybe_improper_list(type1, type2) # proper or improper list
:: nonempty_improper_list(type1, type2) # improper list
:: nonempty_maybe_improper_list(type1, type2) # non-empty proper or improper list
:: Literals # Described in section "Literals"
:: Builtin # Described in section "Built-in types"
:: Remotes # Described in section "Remote types"
:: UserDefined # Described in section "User-defined types"@spec and @typedoc attributes
Now let's look at how to use @spec and @typedoc.
defmodule HelloWorld do
@moduledoc """
This is the HelloWorld module
"""
@doc """
Prints a hello message
## Parameters
- number: integer that will be interpolated in the hello message
## Examples
iex> HelloWorld.hello_number(2)
"hello 2"
"""
@typedoc "The number to be used with the hello message"
@type num :: integer() | float()
@spec hello_number(num) :: String.t
def hello_number(number), do: "hello #{number}"
endNote that @typedoc is used to describe the @type you're defining.
The @spec is being used to specify the function specification.
From a proper coding convention perspective, note that we group @typedoc and @type together and separate it from additional code with a blank line and we keep @spec directly above the function definition with no blank line.
@opaque and @typep
So two module attributes worth mentioning that I didn't know about when I first started learning Elixir are @opaque and @typep.
Now any type defined via @typep is considered private.
@opaque is used to define a public facing type while keeping the structure of the type out of the public documentation.
Writing Documentation Tests in Phoenix and Elixir
If you're interested in understanding how to write documentation tests in Elixir, check out this blog post I wrote{:target="_blank"}.
Documentation NestedFilter and Digger
In learning about Elixir I wrote two hex packages. One was nested_filter{:target="_blank"} and the other was digger{:target="_blank"}. They both contain examples on how to document your Elixir code. If you notice an issue, pull requests are welcome!
Summary
Hopefully you now have a feel for how to document your Elixir code. Even though Elixir is a dynamically typed language, it still gives you the ability to specify your data types via documentation. I really like this because I feel like it can help make the intent of your code more clear.
A Tour of The Kernel Module
Where does to_atom come from?
As I dove deeper into Elixir, I started using guard clauses. So I would end up writing functions with guard clauses that looked like the following:
defmodule Example do
def hello(n) when is_atom(n), do: :hello
def hello(n) when is_list(n), do: ["h", "e", "l", "l", "o"]
endOne day I started wondering where functions like is_atom were coming from and why I never had to call out a module name to have access to them, the way I would have to do with Enum.map/1 as an example.
For the next few sections, we're going to talk about some interesting Kernel functions and cover guard clauses.
Diving Into Kernel's Interesting Functions
The Kernel module has some useful functions that are handy to know as you're going about your day to day Elixir programming.
The is_* functions
The first set of functions that are handy are what I affectionately term the "is_*" (pronounced "is star") functions.
Here's a list and their description straight from the Elixir documentation:
- is_atom - Returns
trueiftermis an atom; otherwise returnsfalse. - is_binary - Returns
trueiftermis a binary; otherwise returnsfalse. - is_bitstring - Returns
trueiftermis a bitstring (including a binary); otherwise returnsfalse. - is_boolean - Returns
trueiftermis a floating-point number; otherwise returnsfalse. - is_float - Returns
trueiftermis a floating-point number; otherwise returnsfalse. - is_function - Returns
trueiftermis a function; otherwise returnsfalse. - is_integer - Returns
trueiftermis an integer; otherwise returnsfalse. - is_list - Returns
trueiftermis a list with zero or more elements; otherwise returnsfalse. - is_number - Returns
trueiftermis either an integer or a floating-point number; otherwise returnsfalse. - is_pid - Returns
trueiftermis a PID (process identifier); otherwise returnsfalse. - is_port - Returns
trueiftermis a port identifier; otherwise returnsfalse. - is_tuple - Returns
trueiftermis a tuple; otherwise returnsfalse. - is_map - Returns
trueiftermis a map; otherwise returnsfalse. - is_nil - Returns
trueiftermisnil,falseotherwise.
Binaries and Bitstrings: A Simple Explanation
One point that deserves a bit of further elaboration is the difference between binaries and bitstrings.
Let's look at an example in code.
iex> is_bitstring "hello"
#=> true
iex> is_bitstring <<1::2>>
#=> true
iex> is_bitstring <<1::8>>
#=> true
iex> is_binary "hello"
#=> true
iex> is_binary <<1::2>>
#=> false
iex> is_binary <<1::8>>
#=> true
iex> bit_size "hello"
#=> 40
iex> bit_size <<1::2>>
#=> 1
iex> bit_size <<1::8>>
#=> 8There's a wonderful explanation from this forum post that describes this perfectly that I will quote here:
In Elixir, a "bitstring" is anything between <> markers, and it contains a contiguous series of bits in memory. If there happen to be 8 of those bits, or 16, or any other number divisible by 8, we call that bitstring a "binary" - a series of bytes. And if those bytes are valid UTF-8, we call that binary a "string".
What does that mean for our example?
Think of strings as a subset of all binaries, and binaries as a subset of all bitstrings. So from the example, you can see that "hello" is 40 bytes long which is divisible by 8. So it is a binary and since it is also valid UTF-8, it is also a string.
The data structure functions
There's some other interesting functions that have to do with maps and lists, so I call them the "data structure functions". Here they are with a description for your convenience.
- bit_size - Returns an integer which is the size in bits of bitstring.
- byte_size - Returns the number of bytes needed to contain bitstring.
- elem - Gets the element at the zero-based index in tuple.
- get_in/2 - Gets a value from a nested structure.
- hd - Returns the head of a list.
- length - Returns the length of list.
- pop_in - Pops a key from the given nested structure.
- put_elem/3 - Inserts value at the given zero-based index in tuple.
- put_in/3 - Puts a value in a nested structure.
- tuple_size/1 - Returns the size of a tuple.
- update_in/3 - Updates a key in a nested structure.
- map_size/1 - Returns the size of a map.
- tl - Returns the tail of a list.
The math functions
There's some other interesting functions that have to do with arithmetic, so I call them the "math functions". Here they are with a description for your convenience.
- div/2 - Performs an integer division.
- round/1 - Rounds a number to the nearest integer.
- max/2 - Returns the biggest of the two given terms according to Erlang’s term ordering.
- min/2 - Returns the smallest of the two given terms according to Erlang’s term ordering.
- +/2 - Arithmetic addition.
- */2 - Arithmetic multiplication.
- //2 - Arithmetic division.
- abs/1 - Returns an integer or float which is the arithmetical absolute value of number.
Miscellaneous functions
Finally, there are some other interesting miscellaneous functions. Here they are with a description for your convenience.
- apply/3 - Invokes the given fun from module with the list of arguments.
- function_exported?/3 - Returns true if module is loaded and contains a public function with the given arity, otherwise false.
- macro_exported?/3 - Returns true if module is loaded and contains a public macro with the given arity, otherwise false.
- self/0 - Returns the PID (process identifier) of the calling process.
- make_ref/0 - Returns an almost unique reference.
Summary
I hope you enjoyed this whirlwind tour of the Kernel module. There's more functions I didn't cover, but I wnated to give you a highlight of some of the ones you would likely use in your coding endeavors.
Digging Into Protocols
Pattern Matching: When You Have a Hammer Everything Looks Like a Nail
So I was coding a new Elixir hex package in the fall of 2017 called Digger{:target="_blank"}. The whole point of this package was to make it easy to ensure any key in a map was a string ("stringify-ing" map keys) or an atom ("atomizing" keys).
At that time, I was familiar enough with Elixir to avoid abusing the "cond" and "case" statements and to use pattern matching.
In atomizing keys, I wound up with a module like the below. Note there is only one public function called "atomize". The rest of the functions are private and support the "atomize" function.
The module to convert map keys to strings had an analogous interface.
defmodule Digger.Atomizer do
@moduledoc """
Documentation for Digger.Atomizer.
"""
@type key :: any
@type value :: any
@type pseudo_map :: any
@doc """
Take a (nested) map and convert string and integer keys to atoms
"""
@spec atomize(map) :: map
def atomize(%{} = map) do
map
|> Map.new(fn{key, value} -> {atomize_key(key), atomize_value(value)} end)
end
defp atomize_value(value) when is_map(value) do
atomize(value)
end
defp atomize_value(value), do: value
defp atomize_key(%_{} = struct), do: struct
defp atomize_key(key) when is_map(key) do
atomize(key)
end
defp atomize_key(key) when is_binary(key) do
String.to_atom(key)
end
defp atomize_key(key) when is_integer(key) do
key |> to_string |> atomize_key
end
defp atomize_key(key), do: key
endIf you look at the above code, you'll notice I started using guards to decide how to atomize a key based on the type of data it was. For example, if it was an integer, the "atomize_key" function used the to_string function to convert the key to a string and then called the. For a struct, I actually wouldn't try and "atomize" it and kept using the struct as the key.
If only there were a mechanism in Elixir so that would let me dynamically call a function depending on a value's type. This would let me more easily extend this module's API for newly defined data types.
Enter Protocols: What Are They?
Before we talk about protocols, we actually have to take a quick detour to talk about polymorphism.
Ok, so what is polymorphism?
From Wikipedia: "In programming languages and type theory, polymorphism (from Greek πολύς, polys, "many, much" and μορφή, morphē, "form, shape") is the provision of a single interface to entities of different types."6
More from Wikipedia:
- Ad hoc polymorphism: when a function denotes different and potentially heterogeneous implementations depending on a limited range of individually specified types and combinations. Ad hoc polymorphism is supported in many languages using function overloading.
- Parametric polymorphism: when code is written without mention of any specific type and thus can be used transparently with any number of new types. In the object-oriented programming community, this is often known as generics or generic programming. In the functional programming community, this is often shortened to polymorphism.
- Subtyping (also called subtype polymorphism or inclusion polymorphism): when a name denotes instances of many different classes related by some common superclass.
Apparently, according to Wikipedia, Elixir uses parametric polymorphism and the functional programming community just refers to it as "polymorphism."
Also interestingly enough, while Elixir is a dynamic language, Wikipedia states "parametric polymorphism is a way to make a language more expressive, while still maintaining full static type-safety."7
Protocols Defined
So after all that, what are protocols?
The Elixir documentation states "Protocols are a mechanism to achieve polymorphism in Elixir."5
In layman's terms that means we depend on function arity and the data types passed in to the function to determine which protocol implementation to dispatch.
Practically speaking, how do you use protocols in Elixir?
You only need to remember 2 syntax keywords when using when working with polymorphism in Elixir: defprotocol and defimpl. As we step through the following case study with the hex package Digger{:target="_blank"}, hopefully it will become more clear.
A Case Study On Using Polymorphism: Rewriting the Digger.Atomizer Module Using Protocols
So now let's step through a small case study by rewriting the Digger.Atomizer module.
Step 1: Define Your Protocol with defprotocol
# file: lib/protocols/atomizer_protocol.ex
defprotocol Digger.Atomizer do
@moduledoc """
Documentation for Digger.Atomizer Protocol
"""
@fallback_to_any true
alias Digger.Types
@doc """
'Atomize' a valid Types.data_type according to the protocol implementation
"""
@spec atomize(Types.data_type, Types.string) :: Types.valid_return_type
def atomize(data_type, atomize \\ :atomize)
endStep 2: Define Your Implementation with defimpl
For string keys, here is the implementation of the protocol.
# file: lib/impl/atomizer/string.ex
defimpl Digger.Atomizer, for: BitString do
def atomize(string, :atomize) do
string
|> String.to_atom
end
def atomize(string, _atomize), do: string
endStep 3: Implement Any as a Fallback
In the following code example, you'll notice we define a protocol implementation for "Any". This is to let Elixir know what to do in case it can't find a function implementation for a particular data type.
In the definition of the protocol itself, we also set the @fallback_to_any attribute to true.
# file: lib/impl/atomizer/any.ex
defimpl Digger.Atomizer, for: Any do
def atomize(any, _atomize), do: any
end
# file: lib/protocols/atomizer_protocol.ex
defprotocol Digger.Atomizer do
@moduledoc """
Documentation for Digger.Atomizer Protocol
"""
@fallback_to_any true
alias Digger.Types
@doc """
'Atomize' a valid Types.data_type according to the protocol implementation
"""
@spec atomize(Types.data_type, Types.string) :: Types.valid_return_type
def atomize(data_type, atomize \\ :atomize)
endAlternatively, you can use the @derive attribute in a module to tell Elixir to use the "Any" implementation for that module.
What if the implementation of Digger.Atomizer.Protocol had not been applicable to any data type?
From the Elixir documentation:
"That’s one of the reasons why @fallback_to_any is an opt-in behaviour. For the majority of protocols, raising an error when a protocol is not implemented is the proper behaviour." "Which technique is best between deriving and falling back to any depends on the use case but, given Elixir developers prefer explicit over implicit, you may see many libraries pushing towards the @derive approach."
Best practices for organizing protocols and their implementation?
- Apparently, it's still an open issue as of 1/15/18 Monday{:target="_blank"}
Other Tips
- According to this blog post{:target="_blank"}, a protocol implementation can use the @for module attribute as an alias of the current target. It's handy for different protocol implementations.
defprotocol ToString do
def to_string(term)
end
defimpl ToString, for: [List, Integer] do
def to_string(term) do
@for.to_string(term)
end
end
ToString.to_string(2)
#=> "2"Summary
Consider using protocols when you find yourself writing functions whose implementation soley depends on the data type(s) being passed in.
Resources:
If you're interested in applying your new knowledge about protocols, check out the Elixir Katas resource I've prepared for you! Just click here to go this web page and sign up with your email to download the free resource
- More reading on questions about approaching polymorphism in functional programming{:target="_blank"}
- Some general reading on polymorphism in object-oriented programming{:target="_blank"}
Footnotes:
Behaviors and Protocols
One thing I've always loved is efficiency. I love checklists and templates so I don't have to think about repeatable processes. Templates can help keep you really organized. When I did some freelancing, I had a contract template that I could edit to quickly make changes. It saved a ton of time.
And what does this have to do with behaviors?
In an analogous fashion to the contracting templates I used to use, Elixir defines behaviors for modules. Behaviors let you define a module and specify what functions must be a part of the module.
Defining Behaviors
The way to define a behavior is through a "@behaviour" attribute. The module whose "behavior" you are implementing must use the @callback attribute to define the functions that are part of the contract it will enforce to all modules that wish to use its "behavior".
In coded English, a behavior does the following
defmodule Hello do
@callback hello(name :: bitstring())::bitstring()
end
defmodule Hello.FirstName do
@behaviour Hello
def hello(name), do: IO.puts "hello #{name}!"
endUse the @callback attribute to specify the functions that are part of the @behavior contract
The @callback attribute in the example above tells Elixir that the "hello" function that takes a bitstring argument must be part of any module that wishes to implement the Hello module behavior.
What happens if you fail to implement the method specified by callback?
I experimented in the iex shell and found I got a warning:
warning: function hello/1 required by behaviour Hello is not implemented (in module Hello.FirstName)
iex:4So no one will revoke your license to program, but it looks like not including the contractualy specified behavior is frowned upon.
Dynamic Dispatching
One interesting thing you can do with behaviors is dynamically dispatching to a specific implementation. Let me give you a quick and contrived example.
defmodule Hello do
@callback hello(name :: bitstring())::bitstring()
def hello_general!(implementation, name \\ "") do
hello_message = implementation.hello(name)
"#{hello_message} You are a General."
end
end
defmodule Hello.FirstName do
@behaviour Hello
def hello(name), do: "hello #{name}!"
end
defmodule Hello.RandomNumber do
@behavior Hello
def hello(name), do: "hello #{name}, your lucky number is #{:rand.uniform(100)}"
endBelow is some sample output from an iex shell:
iex(15)> Hello.hello_general!(Hello.FirstName, "Smith")
"hello Smith! You are a General."
iex(16)> Hello.hello_general!(Hello.RandomNumber, "Murphy")
"hello Murphy, your lucky number is 76 You are a General."Notice how easy it is to dynamically dispatch based on a module.
Relation to Protocols
The following table I pulled from a blog post by a man named Samuel D.8 It gives a nice comparison between protocols and behaviors.
| Protocols | Behaviors |
|---|---|
| Apply to data structures | Apply to modules |
| Specify new implementations of existing functions for new datatypes | Specify a public spec/contract for modules to implement |
| "Here's my datatype, it can X" | "Here's my module, it implements Y" |
| Exclusive to Elixir | Provided by the Erlang runtime |
The main idea is that protocols can be thought of as "template" functions for handling different data types while behaviors can be thought of as "template" contracts that tell modules what functions to implement.
Summary
Elixir behaviors can be a great tool for helping to organize your code by specifying contracts and keeping your coding intentions clear.
Footnotes
Guards
Sometimes I've found myself wanting to only call a certain function depending on a certain condition. For example, I might only want to call a function when one of the parameters is greater than the other.
I did this in a production Phoenix application recently when I was trying to recursively generate a routing path
What is a guard?
Elixir guards are special little clauses denoted with the keyword when that are used to apply extra checks on pattern matched functions.
Here's a quick concrete code snippet:
def generate_path(path, j, k) when k > j and is_integer(j) and is_integer(k), do: pathSo in the above snippet, this function will only be called when the condition "k > j" is met and they are both integers.
Why Use a Guard?
Like I said before, I found myself reaching for guard clauses when I want to apply a check on the parameters I pass into a function.
Types of Functions You Can Use With Guards
So remember in Chapter~\ref{cha:chapter*kernels} A Tour of Kernels, we described the *is** functions like is_integer, is_atom, and so on? Also, do you recall the *data structure functions* such as byte_size, map_size, and so on?
Well those are the functions that are allowed in guards. The complete list is documented in the documentation{:target=_"blank"}.
Why You Can't Use Custom Functions with Guards
You can also use the typical logical operators like &&, ||, and !.
For convenience, I'll quote from the documenation below.
Operators and Functions You Can Use in Guards
Operators
comparison operators (==, !=, ===, !==, >, >=, <, <=)
strictly boolean operators (and, or, not) (the &&, ||, and ! sibling operators are not allowed as they’re not strictly boolean - meaning they don’t require both sides to be booleans)
arithmetic binary operators (+, -, *, /)
arithmetic unary operators (+, -)
binary concatenation operator (<>)
in and not in operators (as long as the right-hand side is a list or a range)Functions
Below are the built-in Elixir functions you can use with guards.
is_atom/1
is_binary/1
is_bitstring/1
is_boolean/1
is_float/1
is_function/1
is_function/2
is_integer/1
is_list/1
is_map/1
is_nil/1
is_number/1
is_pid/1
is_port/1
is_reference/1
is_tuple/1abs/1
binary_part/3
bit_size/1
byte_size/1
div/2
elem/2
hd/1
length/1
map_size/1
node/0
node/1
rem/2
round/1
self/0
tl/1
trunc/1
tuple_size/1The documentation is a quick read that shows you all the details, and I encourage you to give it a read if you're able.
Why You Can't Use Custom Functions With Guards
Once I tried using my custom function as a guard clause. It didn't work.
Why?
With the way Erlang executes functions, each function is tested from top to bottom of the code. If a guard clause were allowed to have a side effect, then you couldn't guarantee functional purity.
To ensure that guard clause functions have no side effects (i.e., "pure functions") and executed quickly, this blog post by Chris Keathley9 stated that Erlang's authors decided to limit guard clause functions to Erlang's built-in functions.
Or Can You Use Custom Functions?
Sort of. You can define your own guards using Elixir macros. However, you still must use Elixir's built-in functions and operators for the guards to be valid.
Example Macro Guard
defmodule Hello do
defmacro is_less_than(m, n) do
quote do: unquote(m) < unquote(n)
end
end
defmodule World do
import Hello
def output_numbers(m, n) when is_less_than(m, n), do: "Hello #{m} #{n}"
def output_numbers(m, n), do: "Hello without numbers"
endIntroducing defguard(p) in Elixir 1.6
As of Elixir 1.610, you now have defguard/1 (or defguardp/1) to define guard macros. This helps you avoid unnecessarily complicated metaprogramming voodoo depending on whether or not the function is being invoked in a guard or not as described in this github issue{:target="_blank"}.
Resources:
If you're interested in applying your new knowledge about guards, check out the Elixir Katas resource I've prepared for you! Just click here to go this web page and sign up with your email to download the free resource
Summary
Overall, I've found guard clauses to be useful, especially when I need to quickly apply a conditional check on function parameters.
IO and Files
Not too long ago I was working on modifying an endpoint in a Phoenix web application that allowed you to upload a CSV file and insert that data into a database table.
In that code I noticed a reference to File.stream!. And so I began digging further.
File Module and Functions
There's a bit of interplay between the File and IO modules in Elixir. Since files are opened in binary mode by default, developers have to use IO.binwrite/2 and IO.binread/2 functions when reading and writing files.
If you want to tell Elixir to to interpret a file as utf8, you can open it with the :utf8 encoding option.
Bang and Non-Bang Function API
The bang file methods (denoted with a ! after the method name) typically raise an error on failure and return :ok on success.
The non-bang functions typically return an error tuple on failure and return :ok on success.
File Function Examples
So let's take a look at some basic file functions. You'll notice quite a few of the functions in the File module are named after their Unix/Linux cousins.
cd/1
Below I set the current working directory.
iex> File.cd("/Users/bruce")
:okstat/2
Next, I get some stats on a file I created in /Users/bruce.
iex(5)> File.stat("toss.txt")
{:ok,
%File.Stat{
access: :read_write,
atime: {{2018, 2, 14}, {17, 49, 50}},
ctime: {{2018, 2, 14}, {17, 49, 50}},
gid: 20,
inode: 18691495,
links: 1,
major_device: 16777218,
minor_device: 0,
mode: 33188,
mtime: {{2018, 2, 14}, {17, 49, 50}},
size: 6,
type: :regular,
uid: 501
}}atime indicates the last time the file was read. For Unix systems, ctime is the last time the file or inode was changed. In Windows, it is the time of creation. The links field indicates the number of links to the file. The size field gives the size of the file in bytes.
chmod/2
Similar to the analagous Unix command, you can change file permissions. The only difference is you use octal flags.
Below is an example.
iex(1)> File.chmod("toss2.txt", 0o040)
:ok
# these are the permissions before calling File.chmod...
-rw-r--r-- 1 bru staff 6 Feb 14 19:59 toss2.txt
# these are the permissions after calling File.chmod...
----r----- 1 bru staff 6 Feb 14 20:05 toss2.txtHere are the flags reprinted from the documentation for your convenience{:target="_blank"}.
0o400 - read permission: owner
0o200 - write permission: owner
0o100 - execute permission: owner
0o040 - read permission: group
0o020 - write permission: group
0o010 - execute permission: group
0o004 - read permission: other
0o002 - write permission: other
0o001 - execute permission: otherdir?
This handy method lets you inquire if a file is a directory.
iex> File.dir?("toss.txt")
falseexists?
You can figure out if the path (or file) exists.
iex(3)> File.exists?("toss.txt")
trueread/1
On success, the read/1 function returns a tuple with a status and binary data object that contains the contents of the file.
iex(5)> File.read("toss.txt")
{:ok, "hello\n"}rename/2
You can also rename files. :ok is returned on success, otherwise {:error, reason} where reason is the reason for the error.
iex(7)> File.rename("toss2.txt", "toss3.txt")
:okregular?
This function checks if a file is "regular". In layman's terms this means it checks to see if it's an executable, a file containing ASCII text, zip file, etc.
You can check on your command line for regularity of a file with:
$ test -f .vimrc && echo regular
regularAs you can see, my .vimrc file is a regular file.
In an Elixir iex shell, you can do:
iex(13)> File.regular?("/Users/bruce")
false
iex(14)> File.regular?(".vimrc")
trueNote that directories in Unix and Linux are "binary files" that locate other files and directories.
write/3
And of course, no File module would be complete without a write function. Below I wrote the word "hello" out to a file called "toss2.txt".
iex(15)> File.write("toss2.txt", "hello", [:write])
:okThere are different modes which are documented here in the File.open/2 method.
Path Module
If you look at the File documentation, you'll notice it typically takes paths as arguments. So I am jotting down some notes about some useful Path functions I found from reading the documentation.
Path Function Examples
absname/1
This handy function converts the path passed in to an absolute path name. For example:
iex(2)> Path.absname("toss.txt")
"/Users/bruce/toss.txt"basename/1
The basename function returns the last component of the path, whether it's a file name or folder, or the path if there are no directory separators.
iex(4)> Path.basename("/Users/bruce/toss.txt")
"toss.txtdirname/1
If a path contains a file name, dirname/1 returns the directory component.
iex(8)> Path.dirname("/Users/bruce/toss.txt")
"/Users/bruce"join/1
This function takes a list of paths and joins them together, removing any trailing slash on the join.
iex(1)> Path.join(["~", "toss.txt"])
"~/toss.txt"wildcard/2
One interesting function I found was the wildcard/2 function. It traverses paths according to the "glob" expression passed and the wildchard characters passed as options.
Here are the special characters from the documentation{:target="_blank"}
? - matches one character
* - matches any number of characters up to the end of the filename, the next dot, or the next slash
** - two adjacent *’s used as a single pattern will match all files and zero or more directories and subdirectories
[char1,char2,...] - matches any of the characters listed; two characters separated by a hyphen will match a range of characters. Do not add spaces before and after the comma as it would then match paths containing the space character itself.
{item1,item2,...} - matches one of the alternatives Do not add spaces before and after the comma as it would then match paths containing the space character itself.IO Module and Functions
I've found myself using the IO module when doing basic debugging when I first started learning Elixir. Namely, I was using IO.puts/2 and IO.inspect/2.
IO Function Examples
But there are also some other handy IO functions.
binread/2
binread/2 lets you read from a "device". If you look at the documentation, this ends up being an atom or pid (process id).
In the example, I read from standard input and pass in the :line option. This lets binread/2 know how to iterate through the device (e.g., line by line or a certain number of bytes).
iex(1)> IO.binread(:stdio, :line)
Hello
"Hello\n"gets/2
gets/2 lets you read one line from an IO device. :stdio is the default device.
In the below example, I specify :stdio to show you the argument parameter, though I didn't actually need to.
iex(5)> IO.gets(:stdio, "What's your name?\n")
What's your name?
Bruce
"Bruce\n"puts/2
When I started with Elixir, the first thing I used to debug code was IO.puts/2.
iex(7)> IO.puts :stdio, "hello"
hello
:okputs/2 writes an item to a device (the default is :stdio) and adds a newline at the end.
iex(1)> m = %{a: 1, b: 2}
%{a: 1, b: 2}
iex(2)> IO.puts m
** (Protocol.UndefinedError) protocol String.Chars not implemented for %{a: 1, b: 2}
(elixir) lib/string/chars.ex:3: String.Chars.impl_for!/1
(elixir) lib/string/chars.ex:22: String.Chars.to_string/1
(elixir) lib/io.ex:553: IO.puts/2As you can see from the error above, puts/2 will not work with maps (or tuples).
inspect/2
Fortunately, Elixir also has inspect/2 which can be useful for debugging. inspect/2 doesn't change the argument passed in but returns it unchanged. So you can use it in your code to get a peak at raw values, including maps and tuples (and other pieces of data where IO.puts/2 will throw an error).
A Word on Inspect.Opts for Debugging
You'll notice in the following example Elixir treats the list of integers as ASCII codes and outputs their letter representation.
iex(8)> t=[97, 98, 99]
'abc'
iex(9)> IO.inspect t
'abc'
'abc'To avoid, this you can turn to the Inspect.Opts module which defines the options used by inspect. To print out numbers, you can pass the :as_lists option as seen below.
iex(10)> IO.inspect t, [charlists: :as_lists]
[97, 98, 99]
'abc'You can review the other options{:target="_blank"}, but one of the most useful ones I've found is the ability to print out a non-truncated list. In the example below you can see I use the :infinity option to see the whole list of numbers from 1 to 100.
Together with :as_lists, this should make your early debugging life much easier.
iex(16)> b = Enum.to_list 1..100
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42,
43, 44, 45, 46, 47, 48, 49, 50, ...]
iex(17)> IO.inspect b, [limit: :infinity]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42,
43, 44, 45, 46, 47, 48, 49, 50, 51, 52, 53, 54, 55, 56, 57, 58, 59, 60, 61, 62,
63, 64, 65, 66, 67, 68, 69, 70, 71, 72, 73, 74, 75, 76, 77, 78, 79, 80, 81, 82,
83, 84, 85, 86, 87, 88, 89, 90, 91, 92, 93, 94, 95, 96, 97, 98, 99, 100]
[1, 2, 3, 4, 5, 6, 7, 8, 9, 10, 11, 12, 13, 14, 15, 16, 17, 18, 19, 20, 21, 22,
23, 24, 25, 26, 27, 28, 29, 30, 31, 32, 33, 34, 35, 36, 37, 38, 39, 40, 41, 42,
43, 44, 45, 46, 47, 48, 49, 50, ...]write/2
write/2 allows you to write to a specified device (standard output is the default device).
iex(3)> IO.write(:stdio, "hello world\n")
hello world
:okWriting Files to Memory
One method I did want to highlight is File.open/2.
iex(1)> {:ok, file_descriptor} = File.open("hello world", [:ram])
{:ok, {:file_descriptor, :ram_file, #Port<0.1181>}}
iex(17)> :file.read(file_descriptor, 12)
{:ok, "hello world"}Doing it this way lets Elixir operate on the data in memory as if it was a file. You'll notice I call an Erlang :file.read method. This is because I couldn't find anything in Elixir to operate on it.
Summary
There's quite a bit more to the File, IO, and Path modules in Elixir. This section gave you just a small taste. The next section will be a simple case study application to help you randomly open files.
Building a Random Image CLI Loader
The best way I have found to learn new concepts is to try and build something with what you just learned. That's why I do all the katas. So to help ingest our learnings for files, let's write a CLI (command line interface) application that helps us pick a set of files to randomly open.
Case Study: Building a Random Image CLI Loader with EScript
I've previously written a tutorial on building an escript CLI application{:target="_blank"}, but we're going to build another one that does a bit more in this post.
Step 1: Initialize a mix application
The first thing to do is to initialize our mix application. I'm passing in the *--sup arguments. This is to initialize the application with some supervisor and umbrella application defaults. It's more for my own amusement than having anything to do with the application.
Below is the mix command I issued and its associated output.
$ mix new image_loader --sup
* creating README.md
* creating .formatter.exs
* creating .gitignore
* creating mix.exs
* creating config
* creating config/config.exs
* creating lib
* creating lib/image_loader.ex
* creating lib/image_loader/application.ex
* creating test
* creating test/test_helper.exs
* creating test/image_loader_test.exs
Your Mix project was created successfully.
You can use "mix" to compile it, test it, and more:
cd image_loader
mix test
Run "mix help" for more commands.I also did a git init . command in the image_loader repository so I could use Git version control.
Step 2: Add yaml-elixir and Write Tests
Next, I add a yaml parser via yaml-elixir in my mix.exs file.
# mix.exs
defmodule ImageLoader.MixProject do
use Mix.Project
def project do
[
app: :image_loader,
version: "0.1.0",
elixir: "~> 1.6",
start_permanent: Mix.env() == :prod,
deps: deps()
]
end
# Run "mix help compile.app" to learn about applications.
def application do
[
extra_applications: [:logger, :yaml_elixir],
mod: {ImageLoader.Application, []}
]
end
# Run "mix help deps" to learn about dependencies.
defp deps do
[
{:yaml_elixir, "~> 1.3.1"}
]
end
endTest Structure
Below are the tests I wrote. Notice I only test the path generation functionality. I could actually check the status of the images when they're opened, but I chose not to do that.
# image_loader_test.exs
defmodule ImageLoaderTest do
use ExUnit.Case
@file_path "/test/fixtures/test.yml"
test "read yaml from file path into map" do
assert ImageLoader.read_yaml_from_file_path(@file_path) ==
%{
"set_1" => %{
"base_path" => "/test/fixtures/",
"directory" => "images/",
"files" => ["pexels-photo-87065.jpeg", "pexels-photo-274054.jpeg"]
}
}
end
test "fetch image paths from yaml file" do
assert ImageLoader.image_paths(@file_path) ==
%{"set_1" => ["#{File.cwd!}/test/fixtures/images/pexels-photo-87065.jpeg",
"#{File.cwd!}/test/fixtures/images/pexels-photo-274054.jpeg"]}
end
endStep 3: Setup Yaml Structure / File
# fixtures/test.yml
set_1:
base_path: "/test/fixtures/"
directory: "images/"
files: ["pexels-photo-87065.jpeg", "pexels-photo-274054.jpeg"]Step 4: Open Images
Below is the code used to randomly open up images. The main functions are image_paths, which produce the file paths to the images so the System.cmd can know which files to open, and open_images, which does the actual work of opening the images.
The function read_yaml_from_file_path parses the yaml file into a map to be parsed through by Elixir.
# image_loader.ex
defmodule ImageLoader do
@moduledoc """
Documentation for ImageLoader.
"""
# Boot up iex and type ImageLoader.open_images("/test/fixtures/test.yml")
def open_images(file_path) do
image_paths(file_path)
|> Enum.map(fn{set_key, files} -> System.cmd("open", files) end)
end
def image_paths(file_path) do
read_yaml_from_file_path(file_path)
|> Enum.reduce(%{}, fn({set, set_info}, acc) -> Map.merge(acc, %{set => assemble_paths_from_set(set_info)}) end)
end
defp assemble_paths_from_set(set_map) do
base_path = Map.get(set_map, "base_path", "")
dir = Map.get(set_map, "directory", "")
Map.get(set_map, "files", [])
|> Enum.map(fn(file) -> Path.join([File.cwd!, base_path, dir, file]) end)
end
def read_yaml_from_file_path(file_path) do
[File.cwd!, file_path]
|> Path.join
|> YamlElixir.read_from_file
end
endStep 5: Convert to Escript
I've written about building a CLI with Escript before{:target="_blank"}, but I'll reiterate the steps here for convenience.
Step 5a: Configure escript in mix.exs
The first thing to do is to specify the module with a "main" function that serves as the main module in mix.exs.
defmodule ImageLoader.MixProject do
use Mix.Project
def project do
[
app: :image_loader,
version: "0.1.0",
elixir: "~> 1.6",
start_permanent: Mix.env() == :prod,
deps: deps(),
escript: escript_config()
]
end
defp escript_config do
[main_module: ImageLoader.Cli]
end
# Run "mix help compile.app" to learn about applications.
def application do
[
extra_applications: [:logger, :yaml_elixir],
mod: {ImageLoader.Application, []}
]
end
# Run "mix help deps" to learn about dependencies.
defp deps do
[
{:yaml_elixir, "~> 1.3.1"}
]
end
endStep 5b: Add a module with a main function
Next, add the module with the main function that you specified in mix.exs.
defmodule ImageLoader.Cli do
def main(args) do
args
|> parse_options
|> output
end
defp parse_options(args) do
{options, _args} = OptionParser.parse!(args,
switches: [path: :string]
)
options
rescue OptionParser.ParseError ->
[error: "parse error in your arguments"]
end
defp output([error: err] = opts) do
IO.puts "Error in opening files: #{err}"
end
defp output(opts) do
ImageLoader.open_images(path(opts))
IO.puts "Images opened from #{path(opts)}"
end
defp path(opts), do: opts |> Keyword.get(:path, "/test/fixtures/test.yml")
endStep 5c: Build the escript
Finally, build the escript.
$ mix escript.buildStep 6: Run the CLI program
Now, you can run the CLI program. Below I run the script using the path to the test.yml file that is included in this program.
$ ./image_loader --path="/test/fixtures/test.yml"Summary
Hopefully this CLI tool has given you a feel for what you can do with some of Elixir's file related modules. Coming up soon, we'll talk about errors in Elixir.
Everyone Makes Mistakes: Errors in Elixir
I once took a class in watercolor painting. The instructor would have us sketch a bit, and then we'd start adding our paint. You had to be very careful not only with the amount of water you used, but also to let certain areas dry before you attempted to paint. Otherwise the colors would run together and there was no going back. There was no such thing as being able to "rescue" errors in watercolor painting.
Fortunately, Elixir does provide error handling.
Elixir Philosophy: Let It Crash
If you hang around the Elixir community long enough, you'll hear phrases like "let it crash." This refers to the fact that Elixir can do things like let an exit message from a dying process be used by a supervisor to decide what to do.
Conventions
In Elixir, the convention is to create a non-bang function such as hello_world/1 that returns a tuple consisting of a status and a result (e.g., {:ok, result} or {:error, reason}).
You also create a bang function that returns the result or raises an exception. For example., hello_world!/1 could return "result" or raise a HelloException.
Error Handling Keywords
Before diving in to error handling, let's go over some of the basic keywords you'll encounter.
try
The try keyword tells Elixir to enter into the block and "try" something that may result in an error.
catch
The catch keyword can be used with try, although as the Elixir documentation points out, it is very uncommon to use it this way. Instead, you'll use it with the throw keyword.
throw
Throw is used in conjunction with catch in situations where it is not possible to get a value without using throw/catch.
rescue
Rescue allows you to specify what happens when a certain exception is raised.
raise
Raise is the keyword that allows you to raise an error in Elixir.
after
The after keyword specifies something that must always happen.
Examples of Try/Rescue
Let's look at using try and rescue in practice.
Example From the Phoenix Framework
Let's say we had a method to fetch a "Car" model in Phoenix. With a bang get!/1 method, an Ecto.NoResultsError is raised.
def get_my_car do
try do
car = Repo.get!(Car, 4)
rescue Ecto.NoResultsError ->
{:error, "not_found"}
end
endYou could also omit the "try" block and simply use rescue.
def get_my_car do
car = Repo.get!(Car, 4)
rescue Ecto.NoResultsError ->
{:error, "not_found"}
endThis example fits the canonical use case of using raise/rescue for exception handling. This is for unexpected situations your program gets into.
Examples of Throw/Catch
When you have expected failures, it's time for throw/catch. I'll summarize the findings from this StackOverflow answer11 on throws which gives some more interesting insights and you can read if you'd like.
The Elixir documentation12 says that throw/catch is good to use when interfacing with library code that does not provide a "proper API".
As an example, let's say Elixir didn't provide a way to delete an element(s) from a list.
Then you might use throw this way:
try do
m = [:t, :u, :v]
Enum.each m, fn(y) ->
if y == :u, do: throw([:t, :v])
end
"Nothing to catch"
catch
list -> list
endOne cool example comes from Ecto:
def transaction(_repo, _opts, fun) do
# Makes transactions "trackable" in tests
send self, {:transaction, fun}
try do
{:ok, fun.()}
catch
:throw, {:ecto_rollback, value} ->
{:error, value}
end
end
def rollback(_repo, value) do
send self, {:rollback, value}
throw {:ecto_rollback, value}
endAbove we can see that we'll catch a rollback when we try a transaction in Ecto.
The StackOverflow post I referenced11 goes on to say that using raise/rescue is good when you want to have a programmer looking at a stacktrace. You can use throw/catch when you don't want to incur the cost of building that stacktrace.
Examples of Try/After
We use try/after when we want to ensure an action occurs no matter what. As an example, we may want to make sure a file gets closed or a status message gets logged.
try do
IO.inspect "Executing some code..."
rescue
err in RuntimeError -> IO.puts "Error #{err}"
after
Logger.info fn -> "We have at least tried to execute some code."
endScope in Try/Rescue/Catch/After
Regarding variable scope, one thing to note is that variables defined in the try/rescue/catch/after context are not available in the "outer context". This is in keeping with traditional Elixir semantics.
So if you're trying to capture a value that is set in a try/catch/rescue/after block, you'll want to do something like this:
status =
try do
raise "failure"
:failure_status
rescue
_ -> :we_are_rescued
end
#status is now set to :we_are_rescuedSummary
Unlike watercolor painting, Elixir provides us with a way to handle our errors. Just like watercolor errors do happen, but we can ensure we have some mechanisms to deal with them when they occur.
Footnotes
Sigils: Or What Are Those Squiggly Things?
My first exposure to something similar to Elixir sigils came via the Ruby programming language's way of specifying literals. I was minding my own business reading the source code and came across something similar to the following:
cars = %w(mustang ranger fiesta)
#=> ["mustang", "ranger", "fiesta"]
brand = cars.inject({}) { |r, car| r.merge({car => "Ford"})}
#=> {"mustang"=>"Ford", "ranger"=>"Ford", "fiesta"=>"Ford"}You can see the %w in Ruby creates an array. But what are sigils and where do they come from?
Sigils: What They Are and a Backstory
Apparently, according to Wikipedia13, sigils were actually popularized by the BASIC programming language. BASIC appended the $ to the names of all strings.
The layman's definition of a sigil is a symbol placed in front of a variable name that shows the variable's scope or data type.
Now I mentioned Ruby's way of specifying literals with the "%" symbol because they will closely match Elixir's sigil syntax. But from the canonical definition of sigil, the $ symbol specifying a Ruby global variable would be an actual example of a sigil in Ruby. But I digress.
Why Use Sigils?
With the use of a symbol, sigils immediately tell you the "type" of variable you are dealing with.
Using Sigils in Elixir
In Elixir sigils are used more closely with the Ruby "literals" example I gave above. They help work with representations of text.
Sigils and Regular Expressions
Elixir's regular expression implementation is based on PCRE (Perl Compatible Regular Expressions)14
The common way to define regular expressions in Elixir is by using "~r". Let's look at the following example.
"World" =~ ~r/world/
#=> falseYou can also use other delimiters such as brackets(~r[yo]), single quotes(~r'yo'), double quotes(~r"yo"), parentheses(~r(yo)), braces(~r{yo}), and double angle brackets(~r
Apparently, you get all these choices of regex delimiters so you can write literals without having to escape delimiters, which as I think about it, is a really nice feature.
Char List/Word List/String Sigils
If you want to generate char lists with single quotes without having to escape them, try the ~c sigil.
~c(John said, 'hi, how are you?')
#=> 'John said, \'hi, how are you?\''If you recall the example I gave with Ruby literals and "%w(mustang ranger fiesta)", Elixir operates with a similar syntax. Below is an example.
~w(mustang ranger fiesta)You can also create atomized lists by placing the letter "a" after the closing delimiter of the sigil. Use the letter "c" for character lists.
~w(mustang ranger fiesta)aFinally, you can also have string sigils.
~s(John said, "hi, how are you?")Date and Time Sigils
Elixir also provides some handy sigils for initializing Date, Time, NaiveDateTime, and Time structs.
Date Sigil
Below is an example of a sigil for Date.
~D[2001-12-25]NaiveDateTime Sigil
Below is an example of a sigil for NaiveDateTime.
~N[2001-12-25 14:10:07]Time Sigil
Below is an example of a sigil for Time.
~T[14:10:00.001]Escaping in Sigils
Elixir provides lowercase sigils which makes room for interpolation and escape codes. The uppercase sigils do not do this.
Below is a list of escape codes that are allowed in strings and char lists from the Elixir documentation, reprinted here for convenience15.
null byte - \0
vertical tab - \v
tab - \t
space - \s
carriage return - \r
newline - \n
form feed - \f
escape - \e
delete - \d
backspace - \b
bell/alert - \a
single backslash - \
single hexadecimal byte - \xDD where D is an integer
represents a Unicode codepoint in hexadecimal (such as \u{1F600}) -
\uDDDD and \u{D...} where D is an integerWriting Custom Sigils
Elixir provides a way for you to write your own custom sigils. You define it by declaring a function header "sigil_{representation}" where representation is a one character identifier.
Notice in the code below the custom sigil function takes 2 arguments, the actual thing that is inside the sigil delimiter and a modifier list.
defmodule CustomSigil do
def sigil_f(arg, []), do: arg |> String.to_float
def sigil_f(arg, [?c]), do: arg |> String.to_float |> Float.round(2)
endTo give a more concrete illustration, I'll show you some output from an iex terminal.
iex(20)> import CustomSigil
CustomSigil
iex(21)> ~f(123.456)
123.456
iex(22)> ~f(123.456)c
123.46Notice how we got to round to 2 places with the "c" modifier.
Summary
Sigils are a handy little tool Elixir gives us for dealing with textual representations of strings. I particularly find them useful when creating Date and Time structs as it means I don't have to type out a whole struct with its arguments.
Footnotes
The Observer and How to Profile Your Memory Usage
When I was first learning Elixir, I built an application that was pulling down statistics from a social media platform via its API. Let's call the application YouTuber to have a name to latch on to. I didn't really understand concepts like tail recursion or even how to use pattern matching all that well.
During the course of building and testing, there was a point where the application started having memory issues and crashing on the Heroku server. I wanted to be able to profile it locally. Fortunately, because Elixir sits on top of Erlang, there is such a tool available to help.
What is observer?
Observer is a great little tool that gives you insight into your whole Elixir application. You can see a graphical representation of your supervision tree, process id numbers, and get a tabular view of all the application processes running.
Why use it?
Once I was at a workshop with a engineer who said he was looking through the code to get an idea of how the supervision tree was setup. If I recall correctly, he said he spent time looking at it, and didn't get too far. Then he opened up the observer and said everything made sense.
Truly, a picture is worth a thousand words.
How to install observer
First, you need to have installed Elixir via the installation guide I wrote in Chapter~\ref{cha:chapter1}.
In 2016, I had trouble starting observer, I would often get errors like:
iex(1)> :observer.start
** (UndefinedFunctionError) function :wx_object.start/3 is undefined (module :wx_object is not available)
:wx_object.start(:observer_wx, [], [])
observer_wx.erl:68: :observer_wx.start/0This was because the Erlang installation I was using was not built with WxWidgets. I recall having to rebuild Erlang with WxWidgets and fiddle around for a few hours with it. On MacOSx, I think I had to install wxmac, the WxWidgets dependency.
Today though, that doesn't seem to be the case. When I installed Elixir/Erlang via the guide I wrote in Chapter~\ref{cha:chapter1}, I didn't need to do this. As an FYI, as I'm writing this, I have Elixir 1.6.x and Erlang 21 installed.
I'd like to say something like YMMV (your mileage may vary), but if you have trouble, feel free to shoot me an email at bruce at binarywebpark dot com with a copy of the error message you're getting, the operating system you're running, and which installation method you tried, and I'll try and debug it.
A Tour of Observer
Ok, so now that you have observer installed, it's time to take a tour of what's available. If you're reading this online and can't see the images in the following section, it's best to grab a PDF copy. This is because the processing software I use isn't compatible with Wordpress at the moment.
Open up an iex shell and type ":observer.start".
Looking at memory
Below is an image of the Memory Usage from the Load Charts tab. You can see the memory usage of your program. This is what I used when I was troubleshooting the memory issues I was having with the Youtuber application.
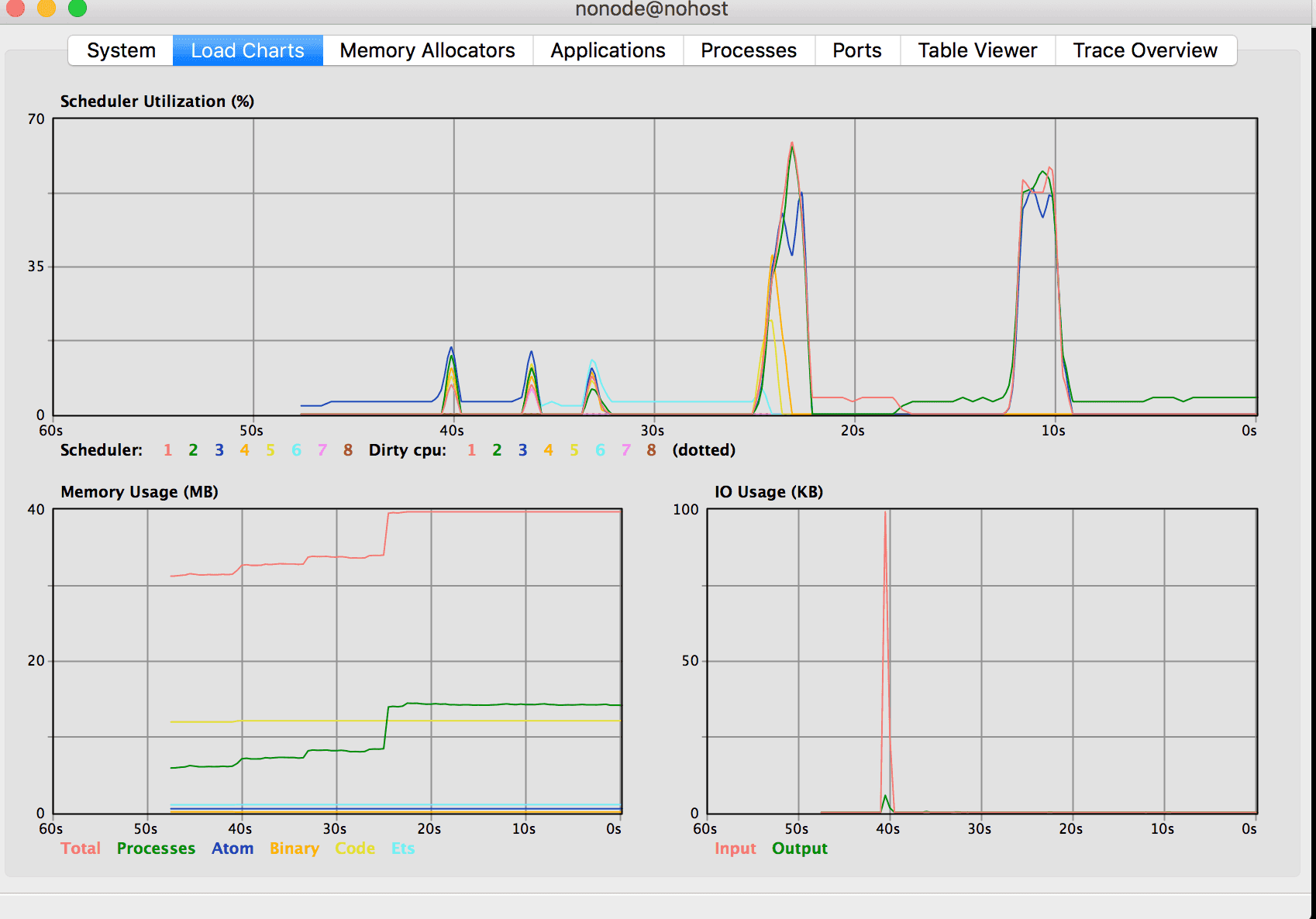
Applications Tab
Below is an image of the supervision tree from the Applications tab. This is the supervision tree graphic the engineer I had mentioned previously used to visualize his company's Erlang program.
Processes Tab
Below is an image of the running processes from the Processes tab.
Summary
Overall, I found observer to be helpful when I was troubleshooting a memory issue with Youtuber. Hopefully, you find it useful too!
Debugging with IEx
One of my favorite debugging techniques doesn't involve any coding tools at all. It just involves moving my mouth and letting a coworker listen and offer suggestions (and vice versa). It's called "rubber ducking".
But to have something to rubber duck about, I often find it's helpful to do a bit of exploratory digging myself. I like to look at the actual value of a computation and expected value in my programs.
And to do that in Elixir, I like to use a tool called IEx.pry.
What is IEx?
IEx is an interactive shell in Elixir.
Understanding Expressions in IEx
IEx expressions are evaluated (as opposed to compiled like production Elixir code).
Getting Help in IEx
There are 2 ways to get help in IEx. You can use the autocomplete or the shell history.
Using autocomplete
Type in however many letters and hit tab. For example, type "M" and hit tab. You should see:
iex(1)> M
Macro Map MapSet MatchError ModuleIf you type in a module name followed by a dot (such as Map.), you'll see:
iex(1)> Map.
delete/2 drop/2 equal?/2
fetch!/2 fetch/2 from_struct/1
get/2 get/3 get_and_update!/3
get_and_update/3 get_lazy/3 has_key?/2
keys/1 merge/2 merge/3
new/0 new/1 new/2
pop/2 pop/3 pop_lazy/3
put/3 put_new/3 put_new_lazy/3
replace!/3 split/2 take/2
to_list/1 update!/3 update/4
values/1That's right, you can get a list of methods for the module. Pretty cool, right?
Using shell history
If you followed the installation instructions in Chapter~\ref{cha:chapter1}, you probably already have shell history enabled by default. If you can press the up arrow and see what you previously typed in IEx, you're golden!
You can also start it on an as-needed basis with:
iex --erl "-kernel shell_history enabled"Aborting IEx
To abort the IEx shell, hit the "control" key and the "c" key simultaneously.
Debbuging with IEx
- IO.inspect (with and without binding)- why not IO.puts?
- IEx.pry
- IEx.break!
- respawn()
User Switch
Connecting to Remote Nodes
.iex.exs file
- example 1 - IEx.pry - exercism example
- example 2 - IEx.pry - phoenix example
- Source: http://bengtwendel.com/your-teacup-is-full-empty-your-cup/↩
- Source: https://softwareengineering.stackexchange.com/questions/30908/difference-between-hash-and-dictionary↩
- Source: https://martinfowler.com/bliki/TwoHardThings.html↩
- Source: Stackoverflow post on char lists↩
- Polymorphism (computer science)↩
- Parametric polymorphism↩
- Documentation of protocols↩
- Source: http://samueldavies.net/2017/04/19/polymorphism-in-elixir-protocols-vs-behaviours/↩
- Source: Using Functions in Elixir Guard Clauses↩
- Source: Elixir v1.6 released↩
- Source: Elixir - try/catch vs try/rescue?↩
- Source: Throws section↩
- Source: Wikipedia↩
- PRCE - Perl Compatible Regular Expressions↩
- Getting Started Docs↩